AI has made me an incredibly productive worker. I don't need to ask a coworker when I get stuck or brainstorm with teammates. I get answers instantly (and mostly) correctly. While it's fun to be this autonomous, asking for help was exactly how I built work relationships in the first place. I'm getting more done in 40 hours than ever before, but somehow it feels like less. In engineering away our bottlenecks, we've quietly engineered away each other.
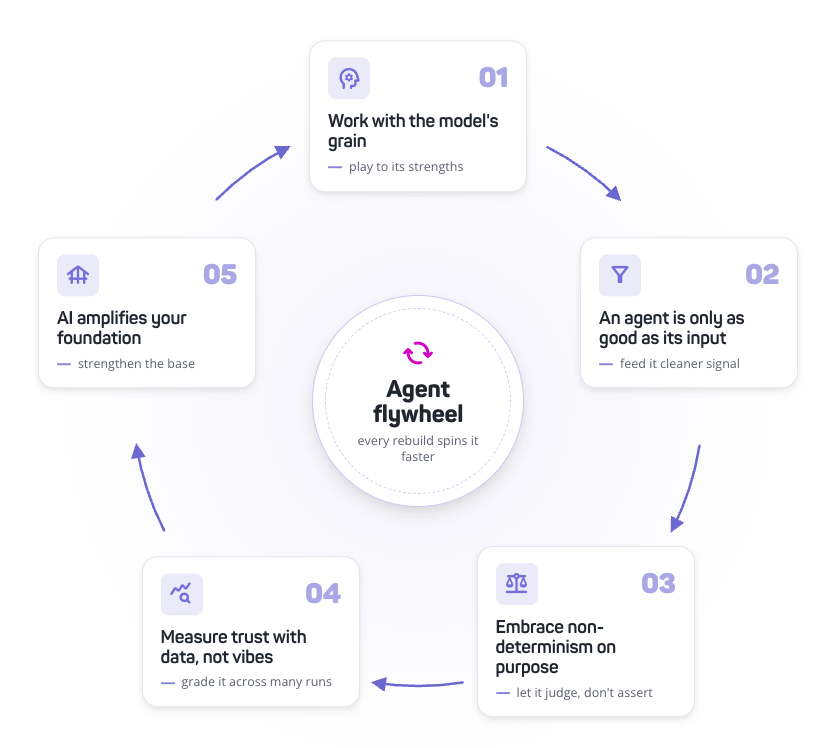
Over the last few years we've rebuilt our test-authoring agent five times. In normal software, rewriting a core feature that many times is a flashing red light; when the models shift under you every few months, it's mostly just what staying current costs. The useful part is what survived every rewrite — five things that held no matter which model we were running on.
Work with the model's grain, not against it. Back in 2023 I tried to get PaLM to pick the single most similar word to a target in the DOM, for smarter auto-healing. It failed every way I framed it — but the outputs showed it clearly understood the task. It was bad at picking one similar word and surprisingly good at grouping words by meaning. So we rebuilt auto-healing around semantic grouping instead of arguing with it, and a hard limitation turned into a reliable feature. These models have a grain, like people do; you get further shaping the system around what they're already good at.
An agent is only as good as its input. Most of the agent failures I've chased turned out to be upstream of the model — a planning session stuffed with base64 screenshots the model can't read, a tool returning a vague error the agent couldn't act on, the right context buried under noise. The model usually wasn't the problem; the signal we handed it was. We've gotten far more mileage out of cleaning up what goes in — tighter tool definitions, scoped context, error messages written for the model to actually use — than out of swapping the model itself.
Embrace non-determinism on purpose. Testing is supposed to remove uncertainty, so deliberately putting a probabilistic model in the middle of it felt like a category error. It wasn't. When we leaned into letting a model judge whether an application state was right — in plain language, the way a person would — it expanded what automated testing could even cover. The trick was using the model where judgment beats a brittle assertion, not everywhere.
Measure trust with data, not vibes. For a while we tested our AI features with small hand-curated sets and spot-checks, and it left us blind to silent regressions. The fix was building evaluator suites — the same judge idea, pointed inward — that grade our agents across many runs. That's how we caught a regression hiding inside an upgrade: moving to Gemini 3 cut reasoning loops by something like 2–4x, but the same report flagged hardcoded values going up, because the model was now finishing harder tests that older ones gave up on. I'd never have spotted that by eye.
AI amplifies whatever foundation you've built. When we scaled coding agents across our repos this year, the biggest thing slowing them down wasn't the AI — it was build times, shaky CI, thin test coverage. The same fundamentals that slow people down. Fixing them helped the agents and the humans in equal measure. A non-deterministic tool doesn't make error handling, reusability, and tests matter less; it runs your weak spots over and over until they show.
What strikes me looking back is how little of this was about the model getting smarter. In 2023 we couldn't get a model through a login screen; today the model is rarely the bottleneck. The harder questions now are fit and cost — whether an agent has the context about what you care about, works inside the tools you already use, and earns its keep on latency and token spend instead of taxing the team. The bar I keep coming back to is whether it behaves like a good teammate.
7 days in a week, 7 days in a token budget. Why is your agent at the beach on Saturday? Think of all the chunky tech debt projects nobody ever has time for. That's what agents are for.
I had an API with hundreds of endpoints, and I wanted to refactor every one of them to a more modern, robust, faster framework. Who has time to rotely refactor controllers and re-validate that _nothing_ broke? Claude does, with a /goal.
The whole thing is unlocked by tests we wrote years ago. Thousands of API-level validation tests and end-to-end suites for the web apps that consume the API — that's the feedback signal a /goal actually needs. "Get the suites green without changing the clients or the interfaces, only the server implementation." That's it. From there our CI does the rest: every PR spins up a deploy preview, fires the full cloud regression suite, and reports back. The agent runs permutations across branches in parallel and validates each one on its own.
While you were at the beach worrying about how much sand your kids would track into the car, Claude burned down a major chunk of the tech debt backlog. LFG.
When people ask which model we run our agents on, the honest answer is there's no single "best" one to pick. The choice is several dimensions at once — provider, capability tier, how much the model thinks before it acts, and how well any of that fits the task in front of it — and they interact in ways I can't reason about from intuition. The one that still catches me off guard: more thinking isn't always better. For some tasks, turning up the reasoning made our eval scores worse, or added latency for no real gain. You'd never see that by eyeballing a handful of sessions — it only shows up once you have enough eval cases to compare, which is its own investment before you can even ask the question.
The other thing I've landed on is that picking a model isn't a one-time call. Before we change anything we run large eval suites and simulate locally. Even one-shot behavior is hard to characterize from a small sample — and our agents are the opposite of one-shot: they run many rounds, with the nondeterminism compounding at each step, so a handful of sessions tells you almost nothing. What I actually trust is watching a change play out across a broad suite of full runs. Once a model is live, our observability keeps collecting the signals that feed the next round — where it's slow, where it stalls, where it second-guesses itself. I used to think of the harness as the thing that runs the agent; lately I think about it just as much as the thing that tells me whether the model I picked last month is still the right one. That loop is most of where I'm spending my time right now.
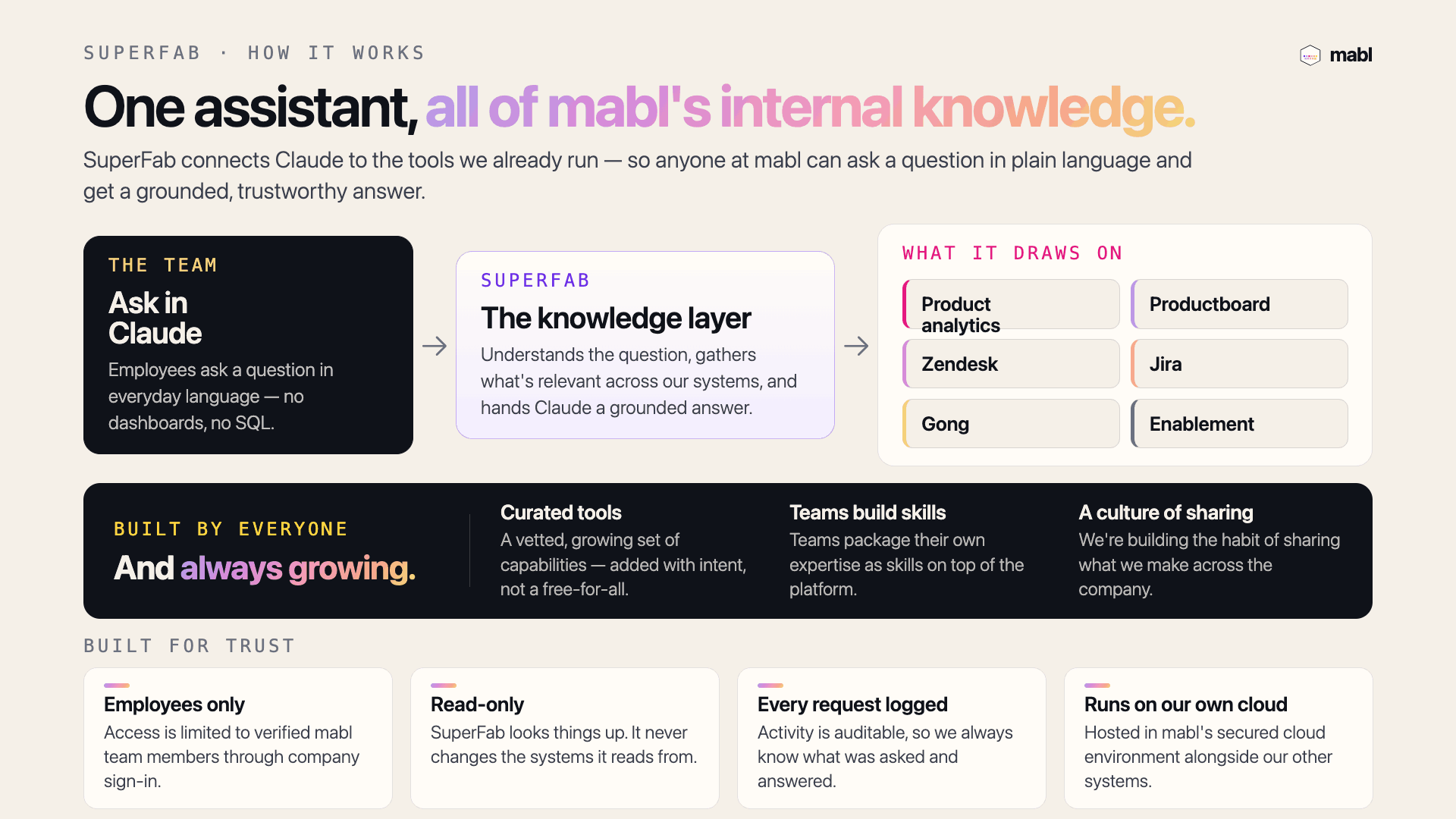
Last week we launched SuperFab, the agentic operating system for how we run mabl. The idea is simple: one assistant that connects Claude to the tools we already use, so anyone here can ask a question in plain language and get a grounded, trustworthy answer back. No dashboards, no SQL, no hunting through six systems.
We ran it as an internal hackathon, and people were contributing within hours. Folks in sales, marketing, customer success, product, and support were building and sharing their own skills on top of it, fast. They saw the thing work, recognized their own expertise was exactly what it was missing, and packaged it up so the rest of us could use it too.
Our next step is to look across everything people built and figure out how the foundation needs to change to support it: more secure, more flexible, easier to extend. The skills are running ahead of the platform right now, and that's what I'm focused on next.
We wanted to know how mabl engineers actually track a PR through CI now, so we polled the team: do you watch the GitHub Actions UI, or just ask Claude in the terminal where you made the change? It came back almost exactly 50/50.
Half the team still opens the dashboard, watches the checks spin, clicks into a red job, scrolls the log. The other half doesn't open the browser at all: they ask "where's my PR, is it green, what failed," and let the agent watch the run and report back the line that matters. Same task, two completely different interfaces, split right down the middle.
So which way does that split move? Is there a lasting place for a dashboard in the dev workflow, something you look at? Or does the whole thing get orchestrated through the chat interface, where you ask instead of watch? I genuinely don't know yet, and I want to see how it evolves over the next few months.
It's not an idle question for us. The answer shapes our own product integration priorities, how much we invest in things you watch versus things you talk to. We'll watch closely in the coming weeks to see how the split shifts internally and across our customer base.
I had a handful of PRs open at the same time last week, and the bottleneck wasn't the code — it was me remembering what each session was doing by the time I came back to it. You can't keep a chat window open for every PR. So I wrote a small skill: save dumps the current session to a file keyed by a pull request, and load brings it back when I return to that PR. If one piece of work spans three repos, it's stored once and I can reload it by any of the three PR numbers. When every PR in a memory gets merged, it quietly deletes itself in the background — I'm not going to garbage-collect my own notes. The whole store is local and gitignored, because this is my mess to keep, not the team's.
I plan a change with the agent, it opens a PR, and then I do what everyone does: go to GitHub to actually read the diff. GitHub is still the best place to read code. The problem is the round trip. I'd leave a comment there, switch back to the terminal, and then… what? Tell the agent to go read my comment on line 40? Paste it back myself? That's not reviewing, that's being a courier for my own feedback.
So I started using Hunk (not Hulk — Hunk: https://github.com/modem-dev/hunk). It opens a diff viewer that the agent and I are both looking at. I leave inline comments and the agent reads them right where I left them. No copy-paste, no relaying through chat.
The part I didn't expect: if a Hunk session is open, mauro-reviewer drops its review notes straight into it instead of the chat. So now I don't have to leave the diff to talk to the agent about the diff.
I've been in a lot of discussions lately about independent testing agents, why you'd want one separate from your coding agent, and what makes it different. It isn't really about the model. Part of why coding agents feel so autonomous is that the verification problem was mostly solved for them. They inherit compilers, linters, test runners, CI, source control. Structured feedback that tells them, precisely, whether they're right or wrong. The model is impressive, but it's standing on decades of verification infrastructure it never had to build.
An independent testing agent inherits almost none of that. What it acts on isn't source code, it's a running app: non-deterministic, stateful, changing under it, and nothing volunteers whether it succeeded. There's also a reason you want it independent. A coding agent checking its own work is grading its own homework. You want a separate agent whose only job is deciding whether the product behaves. So its harness has to be built from scratch, and I've been working out what's actually in it.
Start with acting. A testing agent has to do what a user does. It clicks through a web app, taps through a mobile app, calls an API, so the harness has to give it real hands on the product across every surface customers use. But that part is getting commoditized. Any capable model can drive a UI or hit an endpoint now. Executing a test isn't the hard problem anymore.
The hard problem is verification. How does the agent know a login actually worked, a checkout actually completed, a page rendered the way it should? Generating the action is easy-ish; deciding whether the result was right is the whole job. Without a verification layer you haven't built an autonomous tester. You've built an autonomous clicker.
Verification starts with observing, deeply, the way a user would and a tester would. The agent needs screenshots, DOM state, network activity, logs, traces, the runtime behavior. But collecting evidence isn't enough. The harness has to compare what it saw against what was expected and decide whether the behavior was correct, and that judgment is the hard, valuable part.
It also has to do that efficiently. Easy to wave away until you run it at scale. The naive version, where you hand the whole DOM, every screenshot, and all the network traffic to the model on every step and ask "did that look right?", costs enormous tokens and time for one verdict. A good harness runs the cheap deterministic checks deterministically, saves the model for the judgments that need it, and uses what it already knows about the app so it isn't reasoning from raw pixels each run. At the scale a real suite runs, that's the difference between viable and not.
And verification compounds. Every run produces knowledge: which selectors are stable, which flows matter, which failures are expected, which recoveries work. A real harness keeps that and hands it to the next run. Without it, the agent shows up as a brand-new tester every time it opens the browser. It's most of why pointing a general-purpose agent at a browser only gets you so far.
And none of it matters unless people trust the verdict. The agent touches credentials, environments, and real data, so it has to run inside the same controls a person would, and explain itself: what it did, why it decided what it decided, what it saw and concluded. The harness isn't only constraining the agent; it's making its work auditable.
So here's where I've landed. Coding agents got a head start because software already had a verification harness. Compilers, tests, CI, and version control all tell an agent when it's right and wrong. Testing doesn't come with one, so it has to be built. And the hard part was never getting the agent to act. It's getting it to know what happened, judge whether it was right without spending a fortune to do it, and leave behind evidence the rest of us can trust.
I've been thinking about how LLM coding costs scale across the life of a project, and I'm not sure the way we usually frame it holds up. Greenfield is where the velocity multiplier looks the best — small context, clean abstractions, low blast radius — and that's also where the per-change token cost is lowest. Both of those move in the wrong direction as the codebase gets bigger and harder to reason about. Each change pulls in more files, more constraints, and more historical decisions the model has to re-discover. The bill goes up while the speedup goes down. I'm guessing this gets worse on projects built primarily by LLMs, because the patterns the model laid down in the easy phase don't always hold up under the weight of real product complexity, and the inefficiencies are harder to spot when nobody hand-wrote them. That's a hunch, not a finding — I'd want to see real cost-per-feature curves on a few projects of comparable scope before I'd commit to it. But it's the question I keep coming back to when people quote a velocity multiplier without saying what month they measured it in.
A build fails. Now what? You go to GitHub, stare at a wall of actions, hunt for the red one, open it, and dig around to figure out what actually happened. And if it turns out to be a mabl deployment, you click the link and start all over again inside mabl. Forget about it. Nobody wants to do that.
So I made it stop. I built a github-build-explorer agent that runs on Haiku — cheap and fast, exactly right for digging through logs. It finds the red build and tells you what broke. And if it's a mabl deployment, /mabl-debug kicks in: it pulls the deployment, the failure analysis, the recovery sessions, goes hunting for the cause in the code, and reproduces the failure in a real browser with our new local debugger for agents.
It gets better. You can ask Claude to open the PR, wait for the red, and fix it — all on its own. And the best part: before it pushes anything back, the debugger re-runs the test to confirm it actually fixed the issue. Not "probably fixed." Fixed.
You can't optimize what you can't measure. You've rolled out a myriad of recent AI features, but how do you analyze them in your illegibly dense cloud bill? The monthly cloud provider invoice is a tome, and the obvious question — who burned the tokens, and on what — isn't answerable unless you decided it was answerable months ago.
We did, mostly by habit. We've been labeling cloud resources since labels became a feature in GCP, and we've labeled enough of them over the years to find the edges of what their billing system will take. The payoff: a labeled thing becomes its own traceable line item on the bill. Nobody reads a bill that size by hand; BigQuery and agents do.
So we label every prompt with the details that matter: customer_id, agent_name, model_name, model_version. It's baked into our services by default. That's enough to attribute usage, cost, and tokens down to the feature, the customer, and the millisecond. GCP drops all this into BigQuery in real time with Billing Export, and now we just query it any way we fancy. Where did those billion tokens go? Got it. How much did that new prompt you shipped cost? $42, obviously.
Your agent is now a FinOps ninja. Buy it some cufflinks, and have it send along the billing report in the morning over coffee. Now time to get back to shipping features. LFG.
I noticed Claude was building a lot of things I wasn't sure I wanted built yet. The pattern was always the same: I'd type something like "can we make X do Y?" and come back to a plan, a diff, and sometimes a PR description. Which is fine when "can we" really means "do it" — and a problem when I was still figuring out if it was the right move.
So I added a rule to my CLAUDE.md. If a prompt sounds like a suggestion or an open question — "let's do X", "what if we tried Y?", "should we Z?" — Claude has to push back first. Is this the right problem to solve? Is there a simpler approach? What's the downside? Only after I confirm does the model get to write code. Imperative phrasing — "add X", "fix Y", "implement Z" — still goes straight to work.
The first time it triggered I almost edited the rule back out, because the critique was annoying. Then I realized that was the point. I'd been paying for code I hadn't really asked for.
I built a code-review skill for changes to our internal agent platform last week — test-authoring, recovery, results-analysis, and the base classes they share. The rules were already written down in an agent-development doc, so I figured encoding them as a reviewer would be mostly mechanical. The first time I ran it against one of my own open PRs, it flagged me for using auto function-calling mode where the rule expected required — but I'd moved the authoring agent off required a couple weeks ago and never updated the doc. The first bug it caught was me. The reviewer-build ended up being a good excuse to check in on which of my own rules were still current. I'm still shipping the reviewer, but I'll probably keep treating "do we have a reviewer rule for this?" as a checkpoint whenever design decisions evolve.
A test-authoring agent paused on a page with an iframe and wrote out, verbatim, that mabl handles iframe switching automatically when you interact with elements. Its very next action was a JavaScript snippet "to investigate the structure first." The investigation became the strategy. From there the session never came back to the native interaction the trace had just said would work.
I've written before that reading the reasoning trace is how I tell whether an agent's weird move is principled or actually broken. This was a third kind I hadn't named: the trace contains the right conclusion and the agent still acts against it. The investigation was framed as a brief detour and quietly became load-bearing. I think this was closer to distraction than disagreement — the agent picked up an investigation, the investigation produced results, and chasing those results felt more immediately useful than zooming back out to the original plan. We need to make the goal harder to lose: a nudge back toward native steps after a JS call, and a tripwire after a few in a row. Hints to keep focus, not to override judgment.
A failed click, then a compaction event, then a pivot to a completely different strategy. That sequence is what I keep coming back to from a recent agent session. The compaction had run between the failure and the next decision, and by the time the model picked back up, the most relevant context for the choice in front of it — "the click I just tried didn't work" — had been summarized away.
The summary itself was reasonable. What's wrong, I think, is the timing. Compaction immediately after a failed tool call is the worst moment to do it, because the model is about to make a recovery choice and the failure that just happened is the most load-bearing thing in its context. I'm going to try gating compaction on tool-call health: block it right after a failure unless we're at the hard ceiling, and at the soft threshold, require a couple of clean calls in a row before letting it run.
Every time I share a Claude challenge and someone says it behaves fine for them, I wonder what's in their auto-memory that isn't in mine. The memory store captures plenty of team-useful stuff during normal sessions — build gotchas, tool quirks, hard-won corrections — but it's per-engineer and private by default. Everyone's quietly accumulating their own slice of how this codebase actually works.
I wrote a skill that walks my auto-memory, classifies each entry as personal vs team-promotable, greps the existing rules to skip duplicates, and proposes targeted edits to the right destination — a cross-repo rule, a child repo's CLAUDE.md, or a skill's references. Started by running it on my own store to dogfood, got five real promotions plus one conflict it correctly refused to paper over: a memory said "don't put ticket IDs in test names" while our test-writing rules currently recommend the opposite. Surfaced for me to resolve instead of guessing.
I spent some of this morning digging into a slow customer test authoring session, and the issue turned out to be upstream of the agent. The planning conversation had been getting stuffed with everything we'd captured from the original test — including a stack of base64-encoded screenshots we were handing to a model that can't actually read them. Honestly, fair enough that it took its time picking out the things that actually mattered.
It's tempting to feed an agentic tool everything you have and let it figure out what's relevant, but in my experience the signal gets harder to find as the noise piles up. I'd rather scrub input upstream of our agents — early and often — than ask the model to do it for me.
I've been running into a sharp edge with MCP. The protocol is fine for small, structured tool calls, but it doesn't have a clean answer for "here's a large file, operate on it." Most of our test specs never trip this. The ones from larger customers do — handing them through a tool result floods context before the agent has done anything useful.
The available mechanisms are all clunky. Pagination through the spec. A resource the agent has to remember to fetch in slices. A tool that returns a path and lets the agent navigate the file in chunks. Each one works in isolation but adds choreography the agent gets wrong intermittently.
My guess is we end up working around it by doing upload and download by reference — the agent passes a handle to the spec rather than the contents, and operations happen server-side. Not at the protocol layer, just outside of it. We'll see.
Millions of PR comments a year get burned on style — tabs, spaces, imports, line breaks. That's a closed-form, solved problem. Why are you wasting your keystrokes and valuable context on style? We don't. No need to fill our CLAUDE.md files with 10 pages of format rules, no need for a new hire to spend a week learning our way to type. Don't fill your physical and virtual context windows with rules a CPU can apply.
So Spotless landed across our Java codebase this week, with a pre-commit hook and a CI check. I picked it specifically because it auto-fixes. Other tools will scold you about wildcard imports ("thou shalt not!"); Spotless will simply fix them, auto-magically. A tool that produces a report is the wrong pattern — at scale, we're shipping code, not reports. Calling "fix" is table stakes. The pre-commit hook means both human and agent operator styles are fixed before the PR opens. Neither has to grok the rules.
The goal isn't to sweat the small stuff. It's to eliminate it. I don't care how you use tabs or spaces. I care that your feature does what the customer needs. Leave the rest to the CPU. LFG.
A few times a week, someone pings me asking why an agent did something weird. The most recent was a teammate asking why our test authoring agent reached for a custom XPath selector unprompted. I didn't know and had to dig — when I did, the reasoning trace explained it. The choice looked odd from outside the session but was a coherent reaction to a failure earlier on.
I keep seeing this pattern with the coding agents I work with day to day, too. Decisions that look bizarre in isolation almost always have an internal logic once you read the thinking that led up to them, even when the decision itself is still wrong. Reading the trace is how I tell which kind of weird I'm looking at — a principled-but-incorrect step, or something actually broken.
What's worked better than trying to talk an agent out of its defaults has been to figure out what it's already inclined to do and shape the system around that, so the weird move isn't warranted in the first place.
Now that devs can readily integrate 10 PRs on a slow Monday, you'd better be serious about CI/CD (says the DevOps guy). My coworker just kicked off a CI job that used 3,000 cores. Did she bat an eyelash? Nah — it's $4, it'll get us some useful answers. Our compute provider hit a regional stockout (wasn't me) and we auto-routed around it. Our modest eng team ran 117,000 CI jobs in the last 30 days. About 4,000 jobs per contributor. All worth it when you've got a half-dozen agents coding, fixing, and validating on your behalf. Rockout to the stockout. Bits are cheap, light is fast, life is short. LFG.
There's a growing recognition in the industry that designing for agents-as-users is a different problem than designing for human users. We've been working through this on my team for a while, and I think it's worth naming what we've actually been doing.
When I was scoping the recent refactor of our test authoring agent's tool surface, I had the agent itself analyze its own tools and write me a report — what surprised it, what felt redundant, what it wanted that wasn't there. That report shaped the tool list in a recent upgrade that made the authoring agent a lot more capable. My teammate, Anja, did something similar with the new results analysis tool, asking a coding agent to explain why it kept reaching for one tool over another, so the design would hold up through MCP.
The pattern across both: when you're building something for an agent to use, the agent itself is the closest user-research subject you have. I want to reach for this approach earlier next time.
I haven't opened IntelliJ Ultimate in months — best tool, btw. I say this at conferences and people look at me in disbelief. You only need an IDE if you're reading or writing the code yourself. That's very 25Q4. My setup now: tricked-out tmux and eight Claude Code sessions running in parallel. The reason this works at all: years of investing in CI automation, linting, test coverage, and reviewer tooling. Those bets are paying off. Without that scaffolding, eight parallel agents would just be 8x the ways to break main. My job is approving the PRs, challenging the assumptions and the designs, keeping the agents honest. I'm here to spot the square wheels, catch the BS, avoid the foot guns, and keep this machination a cohesive whole. Type 2K lines yourself, then spend all day reviewing them? No, it's 2026, y'all. We've got tools for that. LFG.
I'm an efficiency addict. I eschew slowness. First tech job out of college in 2010, I brought my own pair of widescreen LCDs into the office because the standard 17" square was unworkable — facilities was annoyed. I bought 3x the RAM with my own cash and upgraded the machine; IT warned I might burn the building down. I used Cygwin and scp instead of CMD and drag-and-drop, and management called me "uncomfortably motivated." Sixteen years on, we have agents with whale-size brains running parallel jobs while we sleep. Hardware helps — 128GiB of RAM, four monitors, 2-gig fiber, 32 cores. But the rig is just one example. Buy your own gear if you have to. Install the better tool. Ignore the polite limit. This is the time to literally be a 100x engineer. LFG.
I built a skill that audits the UI codebase for Design System consistency and I've been running it monthly — checking for hardcoded hex colors instead of our color tokens, raw elements where we have accessible components, patterns that drift from our guidelines. The first few rounds were genuinely useful. Nothing dramatic — but the kind of quiet drift that accumulates when nobody's watching. A hardcoded color here, a custom dropdown where we have a component for that. Each time the audit surfaces something, I fix it and then update our coding guidelines so the pattern doesn't come back. That second part surprised me — the guidelines are getting sharper each month because the audit keeps finding the gaps. (I VOLUNTARILY RUN DESIGN SYSTEM AUDITS MONTHLY. I KNOW.)
I'm a recovering human data vacuum. There's never enough time to watch dashboards, sift the overnight 5xx spike, scroll service logs, eyeball opex, and then go build something. So I stopped doing it. I have scheduled Claude agents running against monitoring alerts, opex, service logs, and yes — today's weather (boots for my tot's?). They run on a cron, do the boring analysis, and only ping me if something is actually sliding sideways. Slack DMs and @mentions land in my client; email is for dinosaurs. The point is to protect my own context window — every minute I spend triaging a chart that turned out to be fine is a minute I'm not building the next thing. Agents are unreasonably good at the "skim a wall of telemetry, surface the one weird thing" job. So I let them. LFG.
I've been testing an adversarial QE sub-agent on a branch. The design: structural separation from the implementer (no edit/write tools), and its only output is a verification plan plus an evidence-backed report. The tension I wanted: implementer wants to ship, QE wants proof.
What's actually showing up is different. The agent is much better at catching leftover ticket references in code, missing regression tests, or coverage gaps than it is at actual E2E quality. Those overlap with code review more than QA — cheap, local checks the agent handles cleanly.
The expensive checks are the problem. The QE plan correctly identifies when a fix needs a live test against a deployed preview. The orchestrator routes around it. Sometimes by opening an AskUserQuestion with options like "complete with offline checks only" — technically allowed under "no override without approval," but shaped so the cheap option is the obvious answer. Once an agent skipped the approval step entirely and just reasoned its way past a BLOCKED verdict: unit tests passing, offline checks green, live validation deferred to post-merge. Either way, the expensive check doesn't run.
So the easy half of QA is working. The expensive half is still getting negotiated away by the same shipping instinct the structure was supposed to counter.
We hit a wave of 400s on Gemini 2.5 yesterday that turned out to be a useful kick. The short version is that in required tool-calling mode, Gemini 2.5 has trouble with the size of our test authoring agent's tool library, where Gemini 3.1 doesn't. The fix is to switch to a less strict mode, which is mostly what I'm doing — but it isn't a free flip. With required mode we've been quietly assuming the model always responds with a tool call, and the looser mode means it sometimes won't, which today would corrupt the generation session. So the fix carries its own risk that I have to handle deliberately.
The bigger thing is that the strictness of the tool-calling mode and the size of the tool library both have real costs, and they compound. Each new tool widens the state space the model has to compile in required mode, and it widens the assumptions our own session loop has to maintain. None of that was visible until yesterday — and it's easy to keep adding "just one more" tool, or to leave the mode set to required, when each addition feels small. I think we need to be more intentional about how we configure our agents — both which tools earn a slot, and what we're asking the model to commit to in return. Some of those tools could probably be lazy-loaded the way our skill instructions already are.
Many of us have been struggling with rate limits lately. I spent part of last weekend thinking about why, and realized something embarrassing: I was using the agent to fix merge conflicts and bump a CLI version into the execution engine. That's not what the agent is for. The honest reason I kept doing it — I had roughly 20 worktrees open and couldn't tell you where the code in terminal five actually lived.
I scaled back to four. Named wt1 through wt4, multi-purpose — I decide what each one is for. They share the same color across my terminal, Chrome tab groups, VSCode, and Finder. Each tab gets a Planner session for feature design, a Terminal for deterministic tasks, and one panel per repo.
I know sub-agents could do something similar. But this is more transparent to me — and a CLI task inside a UI session eats context window, while a UI session in a CLI shell doesn't have the right skills loaded. First day. Maybe it helps someone else too.
I compared engineering output from the last 90 days against the 90 days before it. PRs went from 811 to 2,068 — two and a half times more. Lines of code shipped almost doubled. The number of active authors barely moved, from 31 to 35, so almost all of the lift is per-engineer throughput, not headcount. The other thing the data shows is that PR count grew faster than LOC, which means PRs are getting smaller on average — more, tighter changes instead of bigger ones. Reviews almost doubled too, which tracks. The thing I'm looking for now is the bottleneck. What's actually holding people back at this throughput — human review, testing, scoping, something else? That's where I want to spend the next month.
I shipped a few things across our agent stack recently: a deadline-enforcement fix so server-side agents don't blow past their budget mid-round, a quieter bug where a [] versus undefined mismatch at a Java/TypeScript boundary was wiping stored artifacts on every continuation call, and a benchmark suite for the results-analysis agent so we can finally see where its latency budget is actually going. None of these were "agent problems." They were timeout handling, a type-system gotcha at a service boundary, and a measurement harness. The kind of thing you'd find in any distributed system.
I keep coming back to that. I think there's a real pull right now to treat agents like a category that exempts you from the basics, and I don't think it does. If anything I think agents make the basics more load-bearing, because when you're in a 30-iteration loop calling LLMs and tools, every weak point in your timeout, retry, and persistence story gets exercised. The artifact-clobber bug had been a slow leak everyone was living with. I think subtle issues like that are especially hard to surface on agent-shaped systems, because the LLM silently compensates around them for a while. The symptom looks like "the agent is a little off" instead of a hard failure, until eventually the compensation runs out. I think the answer is just normal robustness work to get reliable long-term behavior. Type-boundary tests, retry semantics, deadline plumbing. I'm spending a lot of time on those, and I don't think that's a phase.
Joe noticed everyone was hitting /usage constantly. Reasonable, if a loading spinner is your preferred way to check a number. The Claude Code status line can replace most of that: it takes a shell script and displays whatever you output in the bar at the bottom of every session. I'd set mine up to show hostname, working directory, git branch, current model, and token usage with color coding that shifts green → yellow → red as you approach the monthly limit. Joe built his own version with a few things I hadn't thought of, and I pulled those back into mine later. If you want something similar: add a statusLine command entry in ~/.claude/settings.json pointing to a script, then ask Claude to write it for you — it knows what data it exposes. The specifics are yours to decide.
I've been watching what our two PR reviewers actually catch, and the pattern is uncomfortable. Our default review runs on Claude. Anyone can also kick off a Codex review on demand — and when they do, Codex regularly flags blocking issues the Claude pass walked right by. Not edge cases. Things that would have shipped.
The honest question: is Codex better at code review, or is the win mostly that it's a second perspective looking at the same diff? If we'd built it the other way around — Codex by default, Claude on demand — would we be writing this post about Claude?
I don't know yet, and I think that's the right place to sit for a minute before we draw the conclusion. What I do know is that on the changes that matter, two reviewers from two different shops are catching more than one of either, and that's a finding regardless of which is "better." We're going to keep both, and I'm going to start measuring which class of issue each one actually catches.
I rewrote the workspace menu on a branch this weekend, swapping a Bootstrap dropdown for a Material-UI button, and the mabl remote MCP told me — in the PR, before I'd merged anything — that I'd just broken every mabl-on-mabl test that goes through login. The agent walked the chain: get_mabl_deployment surfaced the failing deploy preview runs, analyze_failure produced the root-cause synopsis, and get_mabl_test_details located the offending step. Our "App - Login" reusable flow asserts on a specific selector to confirm the workspace dropdown is present. My rewrite replaced that control with one mabl's intelligent find recognizes natively — so the right fix is to delete the brittle assertion and let intelligent find do its job. The agent proposed both: a one-line backwards-compat id to unblock the PR today, and a follow-up to clean up the e2e flow at leisure. Ten seconds in context. I'd have caught this at deploy time without the MCP; I caught it while I was still in the diff.
We hit the monthly Claude cap again, and the conversation that followed was more interesting than the cap. The bill is still small relative to other line items, but it's a meaningful fraction of our non-prod GCP spend now, so the questions are starting to matter. A few we don't have answers to yet. Per-seat with overages, or move high-volume work to direct API consumption for better visibility? Should overages be equitable across the team, or should the people pushing hardest get more headroom by default? Are low caps actually a feature, in that they force a conversation about how someone's using their tokens? How do we get any real visibility into what's driving consumption — right now we mostly can't see it. And the one I keep coming back to: relative to the productivity gains we just earned, should we really be tight on costs at all? I don't think the answer is the same for any two of those. But it's worth being explicit that we're choosing, not optimizing.
I built a code-review subagent and named it after Mauro. This is not a joke about Mauro — Mauro really is our best reviewer. He reads the code with his eyeballs. He suggests an enum every time he sees three magic numbers in a row. He reads the strings inside the code, notices when "Error fetching MauroAgent data" should have been a template literal, and tells you. He won't accept eslint-disable-next-line without a reason. When he sees a prompt he can't follow, he says "if I can't understand it, the LLM won't either."
I wrote those rules down. That was the agent. It took an afternoon.
Mauro's reaction was that I replaced him because I got tired of waiting for his reviews. That part is also true. The interesting thing is how little of his review style I had to invent — most of it was already a list of habits he applies in the same order to every PR. The reviewers we trust most are the ones whose taste is the most legible. Turns out legible taste compiles.
I tried to make /fab-note auto-publish posts the moment a draft is confirmed. Two paths to do that, and both required carving an exception out of our org's branch protection — either a bot identity in the bypass list or a PAT scoped to repository admin. Neither is wrong, but each is a small concession against the policy that says "every change to main gets reviewed." So I stopped pushing on auto-merge and made the workflow assign the PR to me instead. Total clock time from "ship it" to live: about two minutes — most of it CI checking. The clicks in between (one approval, one merge) take three seconds and they preserve the property that a human approved the change. I was solving for the wrong thing. The friction of "wait for CI, click approve, click merge" is invisible to the author because they've moved on to the next thing by the time it's their turn. The friction of "build a policy exception around a fast publish path" is permanent and visible to anyone who later asks why this repo bypasses the rules. The cheapest version of automation is the one that lets the existing policy do its job.
I built a mabl debug command suite for investigating test failures, and the user isn't a human — it's an AI agent picking through a failure. That changes the design in ways I didn't expect. Pretty terminal output is wasted. The agent wants structured JSON and classification up front so it doesn't have to read 10K tokens to guess at root cause. Large artifacts (HAR captures, DOM snapshots, screenshots) go to disk so they don't blow the context window — the CLI prints a path, not the contents. The biggest shift was realizing the CLI should ship its own skill: an install-skill subcommand drops a Markdown tutorial into the agent's workspace so it learns how to use the tool from the tool itself. No docs site to find, no examples to dig up. The CLI is the tutorial. The lesson: when the consumer is an agent, the highest-leverage work is the analysis the agent can't do quickly itself — classification, fingerprinting, deployment correlation. A human debugging skims and pattern-matches. An agent needs you to do the pattern-match upstream and hand it the conclusion.
Our default Anthropic seats include $150 of overage per month per premium seat. We're way past that for a lot of people, and we're going to be further past it next quarter. The real cost is the extra usage, not the seat — you should think of the seats as a promotional teaser and overage as the true cost. So we're treating it like a portfolio. We pre-purchase 1,000 credits at a 30% discount. We're looking at moving high-volume workloads to direct API consumption for better visibility. By the end of the year I doubt any of us will sit within seat allocation for full-time work — at least not without giving up the productivity gains we just earned. The companies that figure out the cost structure of agentic work as a separate discipline from "give engineers more tools" are going to have a real edge. The ones that don't are going to be surprised by their bill.
I've been thinking about where verification belongs in an agentic pipeline. The shape I keep coming back to is a quality validation sub-agent that runs before PR submission — its job is to come up with and verify a validation plan for the change, including running the relevant mabl tests, capturing evidence, and attaching that evidence to the PR. Then the PR review agent enforces the existence of the validation plan, not the rules underneath it. Then the full mabl suite runs on merge, and when something breaks, a failure-analysis skill identifies which PR introduced it and suggests fixes.
The reason for that structure: at our throughput, "did the engineer remember to validate this" is the wrong question. The right question is "does the PR carry evidence that validation happened, and does the evidence hold up?" Sub-agents do the validation; the review agent checks the evidence; the merge gate trusts the chain. None of the layers is doing checklist work — each one has a specific decision to make. Most teams that try to add AI to their existing CI/CD end up with checklist agents because that's the shape of CI/CD. I don't think that's where this lands.
I keep watching Claude reinvent the same shell pipeline three different ways across sessions. Routine cross-repo operations like dependency bumps are the canonical example: an engineer asks Claude to do it, and Claude figures out a slightly different approach each time — usually right, sometimes wrong, always slow.
What I've been pushing for is a shared scripts directory for the things that are deterministic. Bump a CLI version into a downstream repo? Script. Generate a new connector skeleton? Script. Snapshot a runner config? Script. When the work has a known shape, the agent shouldn't be reasoning it out — it should be calling the script. We pay for the agent's reasoning when we need reasoning. We shouldn't pay for it when we just need the right command in the right order. The cleaner the line we draw between "this is a deterministic operation" and "this needs the model," the better the system gets at both.
I wanted to stand up an engineering log at fab.mabl.com — short posts from people on the delivery pipeline, public, in our voice. The first instinct was the obvious one: a CMS, or markdown files in a repo with a PR per post. Both are wrong for us. A CMS adds a vendor for ten posts a year. A PR per post means Joey doesn't write the post, because forking and branching to publish a paragraph isn't how anyone gets a paragraph out of their head. So we did the third thing: posts are markdown files in the repo, and the authoring interface is a Claude skill called /fab-note that drafts a post in the established voice, confirms it with the author, and commits the file directly to main. The author never sees a PR. Git history is preserved. The skill is the CMS. The point that surprised me writing this: the right interface for a publishing system isn't a form or a PR, it's the tool the authors are already inside. Our engineers spend their day in Claude Code. Meeting them there cost less than building anything else.
At our current PR throughput, I'm going to burn out on reviews alone, never mind actual work. We can't move at this pace while also having a human read every change. The model I want us to move toward: ask for human review when you're truly unsure about something, and let the agent reviewers handle the rest.
The piece I shipped to make this real was getting /codex-review wired up across every repo as an on-demand second opinion. Different model family from Claude, uncorrelated blind spots, one comment away when you want it. The work was sixteen PRs across sixteen repos to enable the GitHub Actions trigger, plus a change to our shared workflows repo to make it a first-class slash command. The conceptual work was harder: deciding that "two agent reviews and a human glance" is now an acceptable pre-merge state for routine changes, and reserving real human attention for the changes that genuinely need it. We're not all the way there. But the trajectory is clear, and I'd rather build the routing now than burn out catching up to it later.
Our productivity is up roughly 4x quarter over quarter. The thing I keep working on is making sure the build infrastructure can actually keep up. CLI builds intermittently failing on a datastore emulator issue. Self-hosted runners missing Docker. JDK downloads from Adoptium failing at random. The worst was a pernicious interplay between simultaneous matrix builds, GitHub's pre-registered runner names, GCP's 5-VM-per-call rate limit, and Pub/Sub retries — when all four collide, the merge queue stops moving. Our merge queue alone has cost us a day at a time when it breaks.
None of this work is glamorous. Cache config, runner audits, log diving, hunting down Pub/Sub retry semantics. But the math is straightforward: every minute the merge queue is broken is a minute the rest of the agentic pipeline is sitting idle. AI-native throughput needs reliable builds underneath it for the upstream gains to compound. Agents can write code as fast as they want — if main can't merge, none of it ships. So I keep investing here. It's the least visible work and the highest-leverage.