We hit the monthly Claude cap again, and the conversation that followed was more interesting than the cap. The bill is still small relative to other line items, but it's a meaningful fraction of our non-prod GCP spend now, so the questions are starting to matter. A few we don't have answers to yet. Per-seat with overages, or move high-volume work to direct API consumption for better visibility? Should overages be equitable across the team, or should the people pushing hardest get more headroom by default? Are low caps actually a feature, in that they force a conversation about how someone's using their tokens? How do we get any real visibility into what's driving consumption — right now we mostly can't see it. And the one I keep coming back to: relative to the productivity gains we just earned, should we really be tight on costs at all? I don't think the answer is the same for any two of those. But it's worth being explicit that we're choosing, not optimizing.
AI has made me an incredibly productive worker. I don't need to ask a coworker when I get stuck or brainstorm with teammates. I get answers instantly (and mostly) correctly. While it's fun to be this autonomous, asking for help was exactly how I built work relationships in the first place. I'm getting more done in 40 hours than ever before, but somehow it feels like less. In engineering away our bottlenecks, we've quietly engineered away each other.
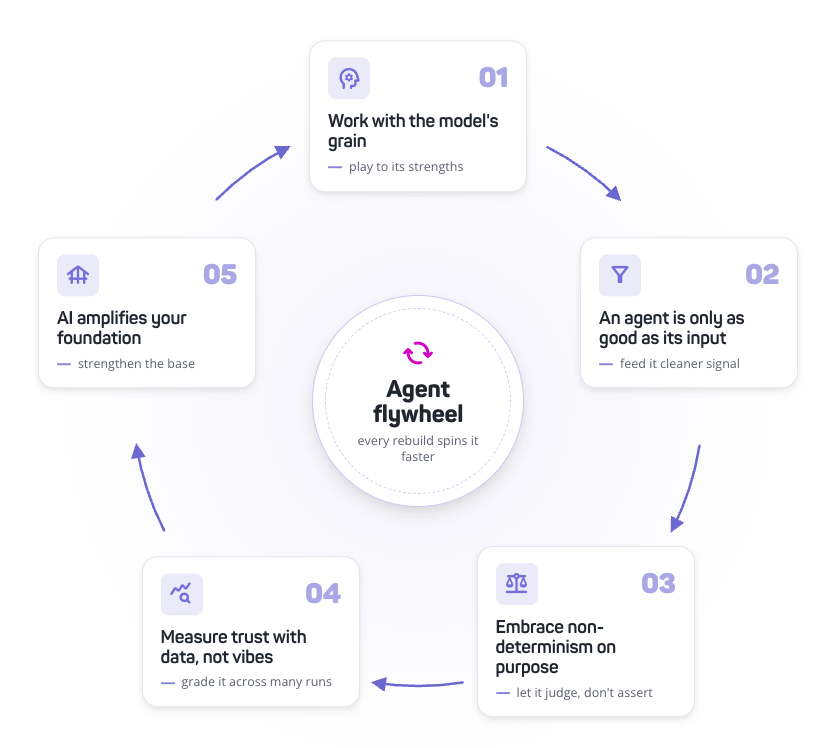
Over the last few years we've rebuilt our test-authoring agent five times. In normal software, rewriting a core feature that many times is a flashing red light; when the models shift under you every few months, it's mostly just what staying current costs. The useful part is what survived every rewrite — five things that held no matter which model we were running on.
Work with the model's grain, not against it. Back in 2023 I tried to get PaLM to pick the single most similar word to a target in the DOM, for smarter auto-healing. It failed every way I framed it — but the outputs showed it clearly understood the task. It was bad at picking one similar word and surprisingly good at grouping words by meaning. So we rebuilt auto-healing around semantic grouping instead of arguing with it, and a hard limitation turned into a reliable feature. These models have a grain, like people do; you get further shaping the system around what they're already good at.
An agent is only as good as its input. Most of the agent failures I've chased turned out to be upstream of the model — a planning session stuffed with base64 screenshots the model can't read, a tool returning a vague error the agent couldn't act on, the right context buried under noise. The model usually wasn't the problem; the signal we handed it was. We've gotten far more mileage out of cleaning up what goes in — tighter tool definitions, scoped context, error messages written for the model to actually use — than out of swapping the model itself.
Embrace non-determinism on purpose. Testing is supposed to remove uncertainty, so deliberately putting a probabilistic model in the middle of it felt like a category error. It wasn't. When we leaned into letting a model judge whether an application state was right — in plain language, the way a person would — it expanded what automated testing could even cover. The trick was using the model where judgment beats a brittle assertion, not everywhere.
Measure trust with data, not vibes. For a while we tested our AI features with small hand-curated sets and spot-checks, and it left us blind to silent regressions. The fix was building evaluator suites — the same judge idea, pointed inward — that grade our agents across many runs. That's how we caught a regression hiding inside an upgrade: moving to Gemini 3 cut reasoning loops by something like 2–4x, but the same report flagged hardcoded values going up, because the model was now finishing harder tests that older ones gave up on. I'd never have spotted that by eye.
AI amplifies whatever foundation you've built. When we scaled coding agents across our repos this year, the biggest thing slowing them down wasn't the AI — it was build times, shaky CI, thin test coverage. The same fundamentals that slow people down. Fixing them helped the agents and the humans in equal measure. A non-deterministic tool doesn't make error handling, reusability, and tests matter less; it runs your weak spots over and over until they show.
What strikes me looking back is how little of this was about the model getting smarter. In 2023 we couldn't get a model through a login screen; today the model is rarely the bottleneck. The harder questions now are fit and cost — whether an agent has the context about what you care about, works inside the tools you already use, and earns its keep on latency and token spend instead of taxing the team. The bar I keep coming back to is whether it behaves like a good teammate.
7 days in a week, 7 days in a token budget. Why is your agent at the beach on Saturday? Think of all the chunky tech debt projects nobody ever has time for. That's what agents are for.
I had an API with hundreds of endpoints, and I wanted to refactor every one of them to a more modern, robust, faster framework. Who has time to rotely refactor controllers and re-validate that _nothing_ broke? Claude does, with a /goal.
The whole thing is unlocked by tests we wrote years ago. Thousands of API-level validation tests and end-to-end suites for the web apps that consume the API — that's the feedback signal a /goal actually needs. "Get the suites green without changing the clients or the interfaces, only the server implementation." That's it. From there our CI does the rest: every PR spins up a deploy preview, fires the full cloud regression suite, and reports back. The agent runs permutations across branches in parallel and validates each one on its own.
While you were at the beach worrying about how much sand your kids would track into the car, Claude burned down a major chunk of the tech debt backlog. LFG.
When people ask which model we run our agents on, the honest answer is there's no single "best" one to pick. The choice is several dimensions at once — provider, capability tier, how much the model thinks before it acts, and how well any of that fits the task in front of it — and they interact in ways I can't reason about from intuition. The one that still catches me off guard: more thinking isn't always better. For some tasks, turning up the reasoning made our eval scores worse, or added latency for no real gain. You'd never see that by eyeballing a handful of sessions — it only shows up once you have enough eval cases to compare, which is its own investment before you can even ask the question.
The other thing I've landed on is that picking a model isn't a one-time call. Before we change anything we run large eval suites and simulate locally. Even one-shot behavior is hard to characterize from a small sample — and our agents are the opposite of one-shot: they run many rounds, with the nondeterminism compounding at each step, so a handful of sessions tells you almost nothing. What I actually trust is watching a change play out across a broad suite of full runs. Once a model is live, our observability keeps collecting the signals that feed the next round — where it's slow, where it stalls, where it second-guesses itself. I used to think of the harness as the thing that runs the agent; lately I think about it just as much as the thing that tells me whether the model I picked last month is still the right one. That loop is most of where I'm spending my time right now.
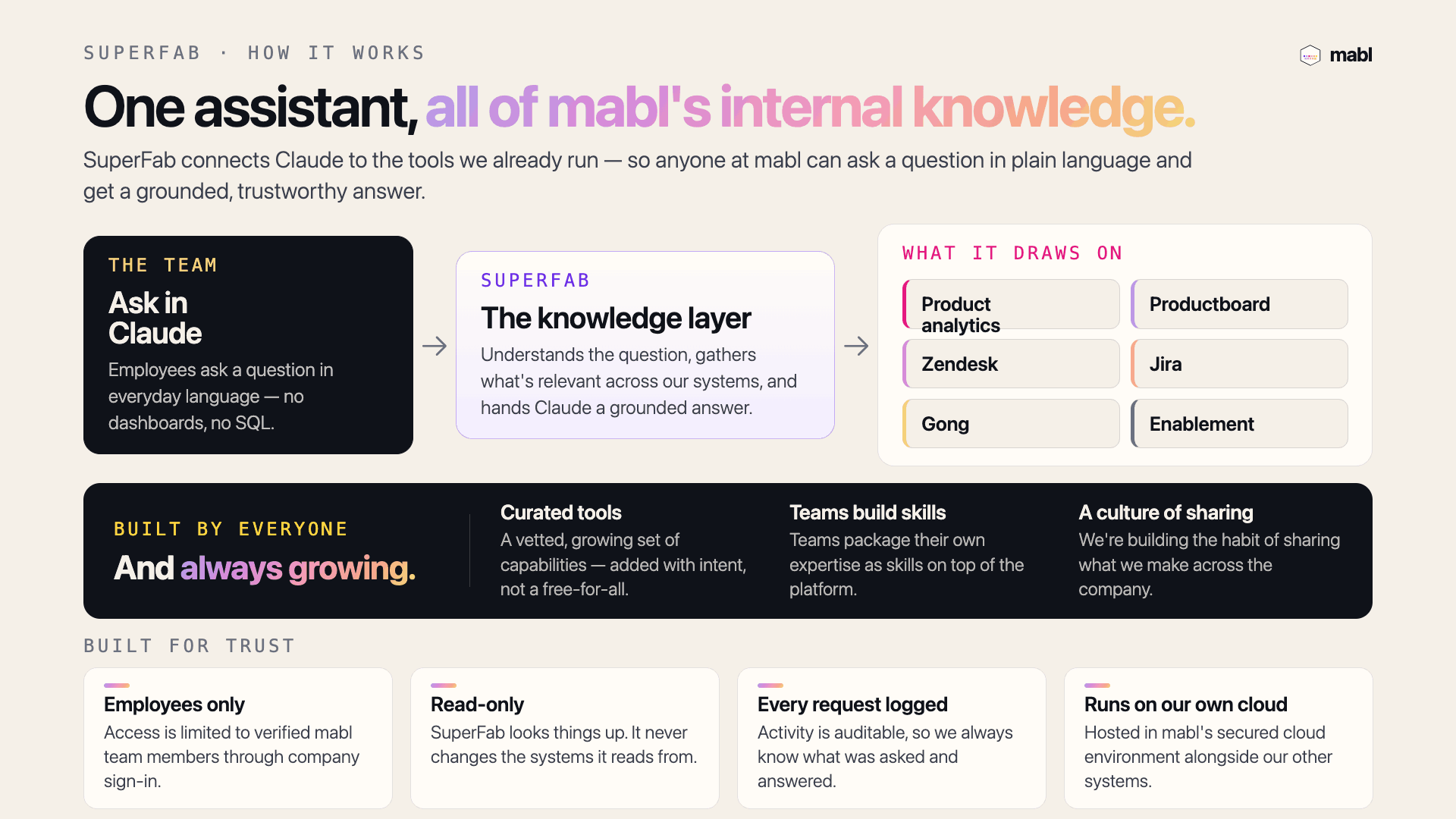
Last week we launched SuperFab, the agentic operating system for how we run mabl. The idea is simple: one assistant that connects Claude to the tools we already use, so anyone here can ask a question in plain language and get a grounded, trustworthy answer back. No dashboards, no SQL, no hunting through six systems.
We ran it as an internal hackathon, and people were contributing within hours. Folks in sales, marketing, customer success, product, and support were building and sharing their own skills on top of it, fast. They saw the thing work, recognized their own expertise was exactly what it was missing, and packaged it up so the rest of us could use it too.
Our next step is to look across everything people built and figure out how the foundation needs to change to support it: more secure, more flexible, easier to extend. The skills are running ahead of the platform right now, and that's what I'm focused on next.