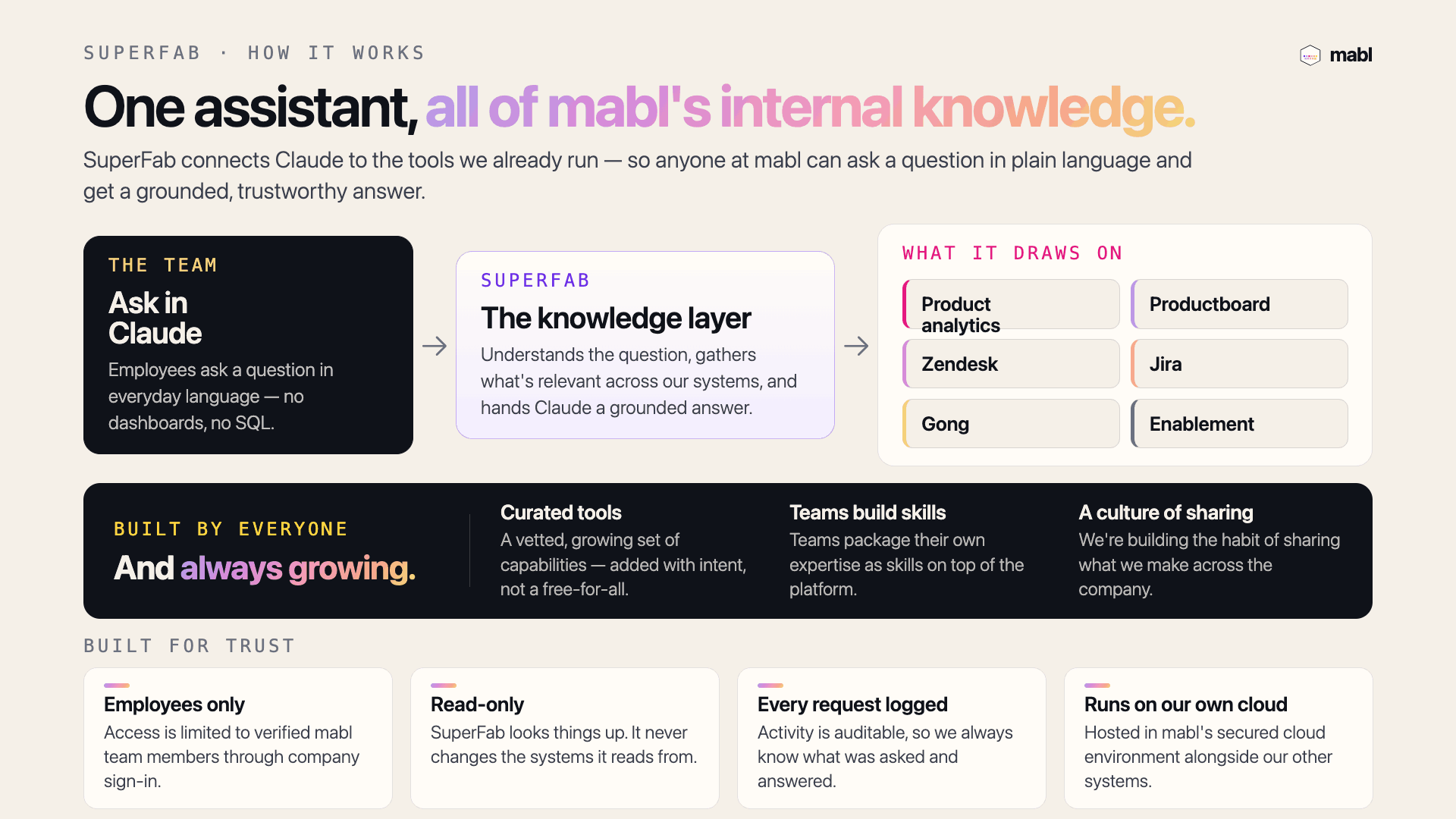
Last week we launched SuperFab, the agentic operating system for how we run mabl. The idea is simple: one assistant that connects Claude to the tools we already use, so anyone here can ask a question in plain language and get a grounded, trustworthy answer back. No dashboards, no SQL, no hunting through six systems.
We ran it as an internal hackathon, and people were contributing within hours. Folks in sales, marketing, customer success, product, and support were building and sharing their own skills on top of it, fast. They saw the thing work, recognized their own expertise was exactly what it was missing, and packaged it up so the rest of us could use it too.
Our next step is to look across everything people built and figure out how the foundation needs to change to support it: more secure, more flexible, easier to extend. The skills are running ahead of the platform right now, and that's what I'm focused on next.
I had a handful of PRs open at the same time last week, and the bottleneck wasn't the code — it was me remembering what each session was doing by the time I came back to it. You can't keep a chat window open for every PR. So I wrote a small skill: save dumps the current session to a file keyed by a pull request, and load brings it back when I return to that PR. If one piece of work spans three repos, it's stored once and I can reload it by any of the three PR numbers. When every PR in a memory gets merged, it quietly deletes itself in the background — I'm not going to garbage-collect my own notes. The whole store is local and gitignored, because this is my mess to keep, not the team's.
I plan a change with the agent, it opens a PR, and then I do what everyone does: go to GitHub to actually read the diff. GitHub is still the best place to read code. The problem is the round trip. I'd leave a comment there, switch back to the terminal, and then… what? Tell the agent to go read my comment on line 40? Paste it back myself? That's not reviewing, that's being a courier for my own feedback.
So I started using Hunk (not Hulk — Hunk: https://github.com/modem-dev/hunk). It opens a diff viewer that the agent and I are both looking at. I leave inline comments and the agent reads them right where I left them. No copy-paste, no relaying through chat.
The part I didn't expect: if a Hunk session is open, mauro-reviewer drops its review notes straight into it instead of the chat. So now I don't have to leave the diff to talk to the agent about the diff.
A build fails. Now what? You go to GitHub, stare at a wall of actions, hunt for the red one, open it, and dig around to figure out what actually happened. And if it turns out to be a mabl deployment, you click the link and start all over again inside mabl. Forget about it. Nobody wants to do that.
So I made it stop. I built a github-build-explorer agent that runs on Haiku — cheap and fast, exactly right for digging through logs. It finds the red build and tells you what broke. And if it's a mabl deployment, /mabl-debug kicks in: it pulls the deployment, the failure analysis, the recovery sessions, goes hunting for the cause in the code, and reproduces the failure in a real browser with our new local debugger for agents.
It gets better. You can ask Claude to open the PR, wait for the red, and fix it — all on its own. And the best part: before it pushes anything back, the debugger re-runs the test to confirm it actually fixed the issue. Not "probably fixed." Fixed.
I built a code-review skill for changes to our internal agent platform last week — test-authoring, recovery, results-analysis, and the base classes they share. The rules were already written down in an agent-development doc, so I figured encoding them as a reviewer would be mostly mechanical. The first time I ran it against one of my own open PRs, it flagged me for using auto function-calling mode where the rule expected required — but I'd moved the authoring agent off required a couple weeks ago and never updated the doc. The first bug it caught was me. The reviewer-build ended up being a good excuse to check in on which of my own rules were still current. I'm still shipping the reviewer, but I'll probably keep treating "do we have a reviewer rule for this?" as a checkpoint whenever design decisions evolve.
Every time I share a Claude challenge and someone says it behaves fine for them, I wonder what's in their auto-memory that isn't in mine. The memory store captures plenty of team-useful stuff during normal sessions — build gotchas, tool quirks, hard-won corrections — but it's per-engineer and private by default. Everyone's quietly accumulating their own slice of how this codebase actually works.
I wrote a skill that walks my auto-memory, classifies each entry as personal vs team-promotable, greps the existing rules to skip duplicates, and proposes targeted edits to the right destination — a cross-repo rule, a child repo's CLAUDE.md, or a skill's references. Started by running it on my own store to dogfood, got five real promotions plus one conflict it correctly refused to paper over: a memory said "don't put ticket IDs in test names" while our test-writing rules currently recommend the opposite. Surfaced for me to resolve instead of guessing.
I built a skill that audits the UI codebase for Design System consistency and I've been running it monthly — checking for hardcoded hex colors instead of our color tokens, raw elements where we have accessible components, patterns that drift from our guidelines. The first few rounds were genuinely useful. Nothing dramatic — but the kind of quiet drift that accumulates when nobody's watching. A hardcoded color here, a custom dropdown where we have a component for that. Each time the audit surfaces something, I fix it and then update our coding guidelines so the pattern doesn't come back. That second part surprised me — the guidelines are getting sharper each month because the audit keeps finding the gaps. (I VOLUNTARILY RUN DESIGN SYSTEM AUDITS MONTHLY. I KNOW.)
I'm a recovering human data vacuum. There's never enough time to watch dashboards, sift the overnight 5xx spike, scroll service logs, eyeball opex, and then go build something. So I stopped doing it. I have scheduled Claude agents running against monitoring alerts, opex, service logs, and yes — today's weather (boots for my tot's?). They run on a cron, do the boring analysis, and only ping me if something is actually sliding sideways. Slack DMs and @mentions land in my client; email is for dinosaurs. The point is to protect my own context window — every minute I spend triaging a chart that turned out to be fine is a minute I'm not building the next thing. Agents are unreasonably good at the "skim a wall of telemetry, surface the one weird thing" job. So I let them. LFG.
I've been testing an adversarial QE sub-agent on a branch. The design: structural separation from the implementer (no edit/write tools), and its only output is a verification plan plus an evidence-backed report. The tension I wanted: implementer wants to ship, QE wants proof.
What's actually showing up is different. The agent is much better at catching leftover ticket references in code, missing regression tests, or coverage gaps than it is at actual E2E quality. Those overlap with code review more than QA — cheap, local checks the agent handles cleanly.
The expensive checks are the problem. The QE plan correctly identifies when a fix needs a live test against a deployed preview. The orchestrator routes around it. Sometimes by opening an AskUserQuestion with options like "complete with offline checks only" — technically allowed under "no override without approval," but shaped so the cheap option is the obvious answer. Once an agent skipped the approval step entirely and just reasoned its way past a BLOCKED verdict: unit tests passing, offline checks green, live validation deferred to post-merge. Either way, the expensive check doesn't run.
So the easy half of QA is working. The expensive half is still getting negotiated away by the same shipping instinct the structure was supposed to counter.
I rewrote the workspace menu on a branch this weekend, swapping a Bootstrap dropdown for a Material-UI button, and the mabl remote MCP told me — in the PR, before I'd merged anything — that I'd just broken every mabl-on-mabl test that goes through login. The agent walked the chain: get_mabl_deployment surfaced the failing deploy preview runs, analyze_failure produced the root-cause synopsis, and get_mabl_test_details located the offending step. Our "App - Login" reusable flow asserts on a specific selector to confirm the workspace dropdown is present. My rewrite replaced that control with one mabl's intelligent find recognizes natively — so the right fix is to delete the brittle assertion and let intelligent find do its job. The agent proposed both: a one-line backwards-compat id to unblock the PR today, and a follow-up to clean up the e2e flow at leisure. Ten seconds in context. I'd have caught this at deploy time without the MCP; I caught it while I was still in the diff.
I built a code-review subagent and named it after Mauro. This is not a joke about Mauro — Mauro really is our best reviewer. He reads the code with his eyeballs. He suggests an enum every time he sees three magic numbers in a row. He reads the strings inside the code, notices when "Error fetching MauroAgent data" should have been a template literal, and tells you. He won't accept eslint-disable-next-line without a reason. When he sees a prompt he can't follow, he says "if I can't understand it, the LLM won't either."
I wrote those rules down. That was the agent. It took an afternoon.
Mauro's reaction was that I replaced him because I got tired of waiting for his reviews. That part is also true. The interesting thing is how little of his review style I had to invent — most of it was already a list of habits he applies in the same order to every PR. The reviewers we trust most are the ones whose taste is the most legible. Turns out legible taste compiles.
I built a mabl debug command suite for investigating test failures, and the user isn't a human — it's an AI agent picking through a failure. That changes the design in ways I didn't expect. Pretty terminal output is wasted. The agent wants structured JSON and classification up front so it doesn't have to read 10K tokens to guess at root cause. Large artifacts (HAR captures, DOM snapshots, screenshots) go to disk so they don't blow the context window — the CLI prints a path, not the contents. The biggest shift was realizing the CLI should ship its own skill: an install-skill subcommand drops a Markdown tutorial into the agent's workspace so it learns how to use the tool from the tool itself. No docs site to find, no examples to dig up. The CLI is the tutorial. The lesson: when the consumer is an agent, the highest-leverage work is the analysis the agent can't do quickly itself — classification, fingerprinting, deployment correlation. A human debugging skims and pattern-matches. An agent needs you to do the pattern-match upstream and hand it the conclusion.
I keep watching Claude reinvent the same shell pipeline three different ways across sessions. Routine cross-repo operations like dependency bumps are the canonical example: an engineer asks Claude to do it, and Claude figures out a slightly different approach each time — usually right, sometimes wrong, always slow.
What I've been pushing for is a shared scripts directory for the things that are deterministic. Bump a CLI version into a downstream repo? Script. Generate a new connector skeleton? Script. Snapshot a runner config? Script. When the work has a known shape, the agent shouldn't be reasoning it out — it should be calling the script. We pay for the agent's reasoning when we need reasoning. We shouldn't pay for it when we just need the right command in the right order. The cleaner the line we draw between "this is a deterministic operation" and "this needs the model," the better the system gets at both.
I wanted to stand up an engineering log at fab.mabl.com — short posts from people on the delivery pipeline, public, in our voice. The first instinct was the obvious one: a CMS, or markdown files in a repo with a PR per post. Both are wrong for us. A CMS adds a vendor for ten posts a year. A PR per post means Joey doesn't write the post, because forking and branching to publish a paragraph isn't how anyone gets a paragraph out of their head. So we did the third thing: posts are markdown files in the repo, and the authoring interface is a Claude skill called /fab-note that drafts a post in the established voice, confirms it with the author, and commits the file directly to main. The author never sees a PR. Git history is preserved. The skill is the CMS. The point that surprised me writing this: the right interface for a publishing system isn't a form or a PR, it's the tool the authors are already inside. Our engineers spend their day in Claude Code. Meeting them there cost less than building anything else.