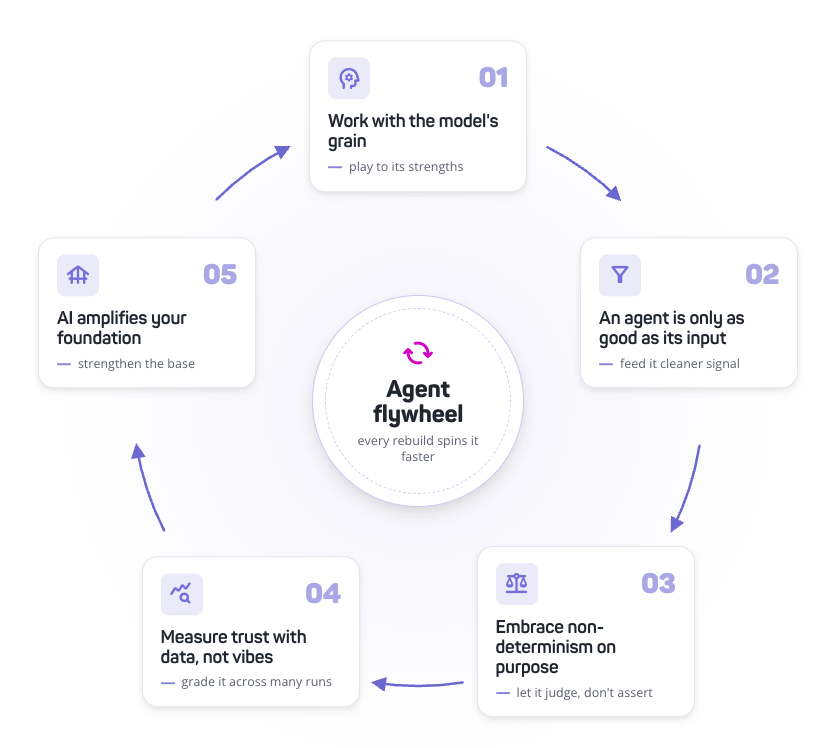
Three agent bugs that turned out to be timeouts, type boundaries, and missing benchmarks.
I shipped a few things across our agent stack recently: a deadline-enforcement fix so server-side agents don't blow past their budget mid-round, a quieter bug where a
I keep coming back to that. I think there's a real pull right now to treat agents like a category that exempts you from the basics, and I don't think it does. If anything I think agents make the basics more load-bearing, because when you're in a 30-iteration loop calling LLMs and tools, every weak point in your timeout, retry, and persistence story gets exercised. The artifact-clobber bug had been a slow leak everyone was living with. I think subtle issues like that are especially hard to surface on agent-shaped systems, because the LLM silently compensates around them for a while. The symptom looks like "the agent is a little off" instead of a hard failure, until eventually the compensation runs out. I think the answer is just normal robustness work to get reliable long-term behavior. Type-boundary tests, retry semantics, deadline plumbing. I'm spending a lot of time on those, and I don't think that's a phase.
[] versus undefined mismatch at a Java/TypeScript boundary was wiping stored artifacts on every continuation call, and a benchmark suite for the results-analysis agent so we can finally see where its latency budget is actually going. None of these were "agent problems." They were timeout handling, a type-system gotcha at a service boundary, and a measurement harness. The kind of thing you'd find in any distributed system.I keep coming back to that. I think there's a real pull right now to treat agents like a category that exempts you from the basics, and I don't think it does. If anything I think agents make the basics more load-bearing, because when you're in a 30-iteration loop calling LLMs and tools, every weak point in your timeout, retry, and persistence story gets exercised. The artifact-clobber bug had been a slow leak everyone was living with. I think subtle issues like that are especially hard to surface on agent-shaped systems, because the LLM silently compensates around them for a while. The symptom looks like "the agent is a little off" instead of a hard failure, until eventually the compensation runs out. I think the answer is just normal robustness work to get reliable long-term behavior. Type-boundary tests, retry semantics, deadline plumbing. I'm spending a lot of time on those, and I don't think that's a phase.