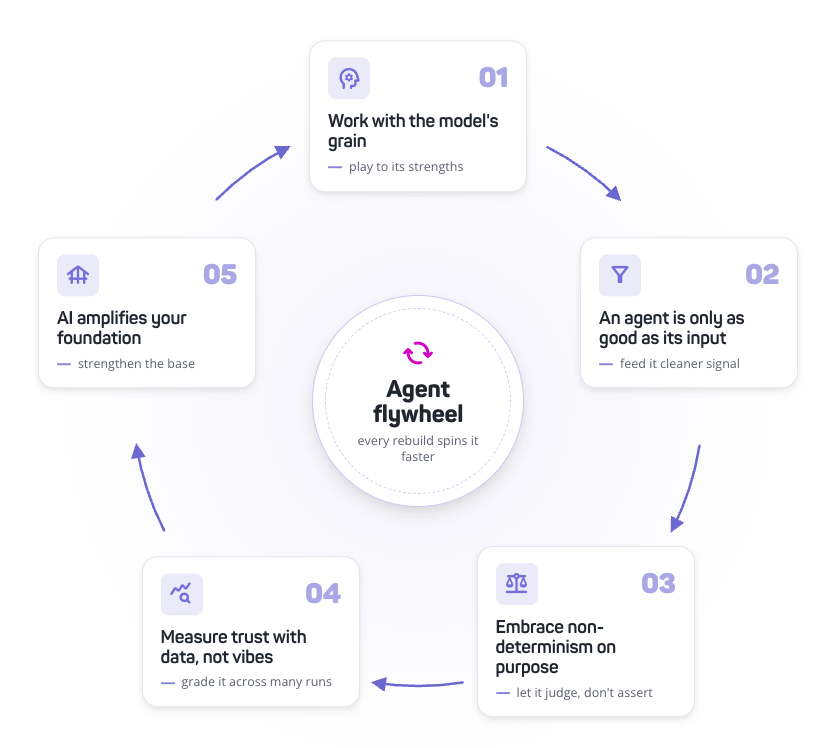
Why I think we need to be picky about our agent configuration
We hit a wave of 400s on Gemini 2.5 yesterday that turned out to be a useful kick. The short version is that in required tool-calling mode, Gemini 2.5 has trouble with the size of our test authoring agent's tool library, where Gemini 3.1 doesn't. The fix is to switch to a less strict mode, which is mostly what I'm doing — but it isn't a free flip. With required mode we've been quietly assuming the model always responds with a tool call, and the looser mode means it sometimes won't, which today would corrupt the generation session. So the fix carries its own risk that I have to handle deliberately.
The bigger thing is that the strictness of the tool-calling mode and the size of the tool library both have real costs, and they compound. Each new tool widens the state space the model has to compile in required mode, and it widens the assumptions our own session loop has to maintain. None of that was visible until yesterday — and it's easy to keep adding "just one more" tool, or to leave the mode set to required, when each addition feels small. I think we need to be more intentional about how we configure our agents — both which tools earn a slot, and what we're asking the model to commit to in return. Some of those tools could probably be lazy-loaded the way our skill instructions already are.
The bigger thing is that the strictness of the tool-calling mode and the size of the tool library both have real costs, and they compound. Each new tool widens the state space the model has to compile in required mode, and it widens the assumptions our own session loop has to maintain. None of that was visible until yesterday — and it's easy to keep adding "just one more" tool, or to leave the mode set to required, when each addition feels small. I think we need to be more intentional about how we configure our agents — both which tools earn a slot, and what we're asking the model to commit to in return. Some of those tools could probably be lazy-loaded the way our skill instructions already are.