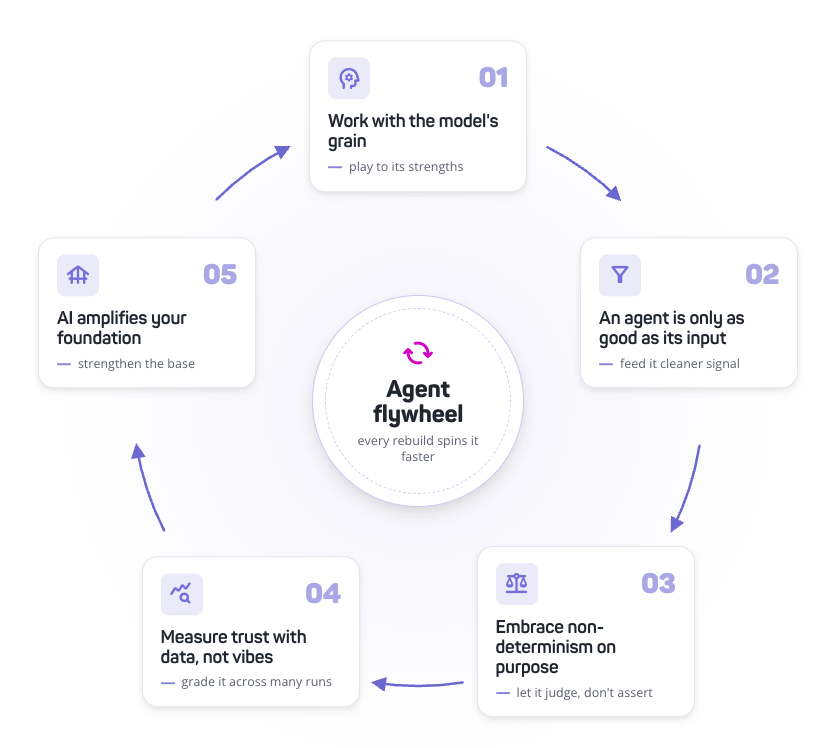
Over the last few years we've rebuilt our test-authoring agent five times. In normal software, rewriting a core feature that many times is a flashing red light; when the models shift under you every few months, it's mostly just what staying current costs. The useful part is what survived every rewrite — five things that held no matter which model we were running on.
Work with the model's grain, not against it. Back in 2023 I tried to get PaLM to pick the single most similar word to a target in the DOM, for smarter auto-healing. It failed every way I framed it — but the outputs showed it clearly understood the task. It was bad at picking one similar word and surprisingly good at grouping words by meaning. So we rebuilt auto-healing around semantic grouping instead of arguing with it, and a hard limitation turned into a reliable feature. These models have a grain, like people do; you get further shaping the system around what they're already good at.
An agent is only as good as its input. Most of the agent failures I've chased turned out to be upstream of the model — a planning session stuffed with base64 screenshots the model can't read, a tool returning a vague error the agent couldn't act on, the right context buried under noise. The model usually wasn't the problem; the signal we handed it was. We've gotten far more mileage out of cleaning up what goes in — tighter tool definitions, scoped context, error messages written for the model to actually use — than out of swapping the model itself.
Embrace non-determinism on purpose. Testing is supposed to remove uncertainty, so deliberately putting a probabilistic model in the middle of it felt like a category error. It wasn't. When we leaned into letting a model judge whether an application state was right — in plain language, the way a person would — it expanded what automated testing could even cover. The trick was using the model where judgment beats a brittle assertion, not everywhere.
Measure trust with data, not vibes. For a while we tested our AI features with small hand-curated sets and spot-checks, and it left us blind to silent regressions. The fix was building evaluator suites — the same judge idea, pointed inward — that grade our agents across many runs. That's how we caught a regression hiding inside an upgrade: moving to Gemini 3 cut reasoning loops by something like 2–4x, but the same report flagged hardcoded values going up, because the model was now finishing harder tests that older ones gave up on. I'd never have spotted that by eye.
AI amplifies whatever foundation you've built. When we scaled coding agents across our repos this year, the biggest thing slowing them down wasn't the AI — it was build times, shaky CI, thin test coverage. The same fundamentals that slow people down. Fixing them helped the agents and the humans in equal measure. A non-deterministic tool doesn't make error handling, reusability, and tests matter less; it runs your weak spots over and over until they show.
What strikes me looking back is how little of this was about the model getting smarter. In 2023 we couldn't get a model through a login screen; today the model is rarely the bottleneck. The harder questions now are fit and cost — whether an agent has the context about what you care about, works inside the tools you already use, and earns its keep on latency and token spend instead of taxing the team. The bar I keep coming back to is whether it behaves like a good teammate.
When people ask which model we run our agents on, the honest answer is there's no single "best" one to pick. The choice is several dimensions at once — provider, capability tier, how much the model thinks before it acts, and how well any of that fits the task in front of it — and they interact in ways I can't reason about from intuition. The one that still catches me off guard: more thinking isn't always better. For some tasks, turning up the reasoning made our eval scores worse, or added latency for no real gain. You'd never see that by eyeballing a handful of sessions — it only shows up once you have enough eval cases to compare, which is its own investment before you can even ask the question.
The other thing I've landed on is that picking a model isn't a one-time call. Before we change anything we run large eval suites and simulate locally. Even one-shot behavior is hard to characterize from a small sample — and our agents are the opposite of one-shot: they run many rounds, with the nondeterminism compounding at each step, so a handful of sessions tells you almost nothing. What I actually trust is watching a change play out across a broad suite of full runs. Once a model is live, our observability keeps collecting the signals that feed the next round — where it's slow, where it stalls, where it second-guesses itself. I used to think of the harness as the thing that runs the agent; lately I think about it just as much as the thing that tells me whether the model I picked last month is still the right one. That loop is most of where I'm spending my time right now.
I built a code-review skill for changes to our internal agent platform last week — test-authoring, recovery, results-analysis, and the base classes they share. The rules were already written down in an agent-development doc, so I figured encoding them as a reviewer would be mostly mechanical. The first time I ran it against one of my own open PRs, it flagged me for using auto function-calling mode where the rule expected required — but I'd moved the authoring agent off required a couple weeks ago and never updated the doc. The first bug it caught was me. The reviewer-build ended up being a good excuse to check in on which of my own rules were still current. I'm still shipping the reviewer, but I'll probably keep treating "do we have a reviewer rule for this?" as a checkpoint whenever design decisions evolve.
A test-authoring agent paused on a page with an iframe and wrote out, verbatim, that mabl handles iframe switching automatically when you interact with elements. Its very next action was a JavaScript snippet "to investigate the structure first." The investigation became the strategy. From there the session never came back to the native interaction the trace had just said would work.
I've written before that reading the reasoning trace is how I tell whether an agent's weird move is principled or actually broken. This was a third kind I hadn't named: the trace contains the right conclusion and the agent still acts against it. The investigation was framed as a brief detour and quietly became load-bearing. I think this was closer to distraction than disagreement — the agent picked up an investigation, the investigation produced results, and chasing those results felt more immediately useful than zooming back out to the original plan. We need to make the goal harder to lose: a nudge back toward native steps after a JS call, and a tripwire after a few in a row. Hints to keep focus, not to override judgment.
A failed click, then a compaction event, then a pivot to a completely different strategy. That sequence is what I keep coming back to from a recent agent session. The compaction had run between the failure and the next decision, and by the time the model picked back up, the most relevant context for the choice in front of it — "the click I just tried didn't work" — had been summarized away.
The summary itself was reasonable. What's wrong, I think, is the timing. Compaction immediately after a failed tool call is the worst moment to do it, because the model is about to make a recovery choice and the failure that just happened is the most load-bearing thing in its context. I'm going to try gating compaction on tool-call health: block it right after a failure unless we're at the hard ceiling, and at the soft threshold, require a couple of clean calls in a row before letting it run.
I spent some of this morning digging into a slow customer test authoring session, and the issue turned out to be upstream of the agent. The planning conversation had been getting stuffed with everything we'd captured from the original test — including a stack of base64-encoded screenshots we were handing to a model that can't actually read them. Honestly, fair enough that it took its time picking out the things that actually mattered.
It's tempting to feed an agentic tool everything you have and let it figure out what's relevant, but in my experience the signal gets harder to find as the noise piles up. I'd rather scrub input upstream of our agents — early and often — than ask the model to do it for me.
A few times a week, someone pings me asking why an agent did something weird. The most recent was a teammate asking why our test authoring agent reached for a custom XPath selector unprompted. I didn't know and had to dig — when I did, the reasoning trace explained it. The choice looked odd from outside the session but was a coherent reaction to a failure earlier on.
I keep seeing this pattern with the coding agents I work with day to day, too. Decisions that look bizarre in isolation almost always have an internal logic once you read the thinking that led up to them, even when the decision itself is still wrong. Reading the trace is how I tell which kind of weird I'm looking at — a principled-but-incorrect step, or something actually broken.
What's worked better than trying to talk an agent out of its defaults has been to figure out what it's already inclined to do and shape the system around that, so the weird move isn't warranted in the first place.
There's a growing recognition in the industry that designing for agents-as-users is a different problem than designing for human users. We've been working through this on my team for a while, and I think it's worth naming what we've actually been doing.
When I was scoping the recent refactor of our test authoring agent's tool surface, I had the agent itself analyze its own tools and write me a report — what surprised it, what felt redundant, what it wanted that wasn't there. That report shaped the tool list in a recent upgrade that made the authoring agent a lot more capable. My teammate, Anja, did something similar with the new results analysis tool, asking a coding agent to explain why it kept reaching for one tool over another, so the design would hold up through MCP.
The pattern across both: when you're building something for an agent to use, the agent itself is the closest user-research subject you have. I want to reach for this approach earlier next time.
We hit a wave of 400s on Gemini 2.5 yesterday that turned out to be a useful kick. The short version is that in required tool-calling mode, Gemini 2.5 has trouble with the size of our test authoring agent's tool library, where Gemini 3.1 doesn't. The fix is to switch to a less strict mode, which is mostly what I'm doing — but it isn't a free flip. With required mode we've been quietly assuming the model always responds with a tool call, and the looser mode means it sometimes won't, which today would corrupt the generation session. So the fix carries its own risk that I have to handle deliberately.
The bigger thing is that the strictness of the tool-calling mode and the size of the tool library both have real costs, and they compound. Each new tool widens the state space the model has to compile in required mode, and it widens the assumptions our own session loop has to maintain. None of that was visible until yesterday — and it's easy to keep adding "just one more" tool, or to leave the mode set to required, when each addition feels small. I think we need to be more intentional about how we configure our agents — both which tools earn a slot, and what we're asking the model to commit to in return. Some of those tools could probably be lazy-loaded the way our skill instructions already are.
I shipped a few things across our agent stack recently: a deadline-enforcement fix so server-side agents don't blow past their budget mid-round, a quieter bug where a [] versus undefined mismatch at a Java/TypeScript boundary was wiping stored artifacts on every continuation call, and a benchmark suite for the results-analysis agent so we can finally see where its latency budget is actually going. None of these were "agent problems." They were timeout handling, a type-system gotcha at a service boundary, and a measurement harness. The kind of thing you'd find in any distributed system.
I keep coming back to that. I think there's a real pull right now to treat agents like a category that exempts you from the basics, and I don't think it does. If anything I think agents make the basics more load-bearing, because when you're in a 30-iteration loop calling LLMs and tools, every weak point in your timeout, retry, and persistence story gets exercised. The artifact-clobber bug had been a slow leak everyone was living with. I think subtle issues like that are especially hard to surface on agent-shaped systems, because the LLM silently compensates around them for a while. The symptom looks like "the agent is a little off" instead of a hard failure, until eventually the compensation runs out. I think the answer is just normal robustness work to get reliable long-term behavior. Type-boundary tests, retry semantics, deadline plumbing. I'm spending a lot of time on those, and I don't think that's a phase.