I built a code-review skill for changes to our internal agent platform last week — test-authoring, recovery, results-analysis, and the base classes they share. The rules were already written down in an agent-development doc, so I figured encoding them as a reviewer would be mostly mechanical. The first time I ran it against one of my own open PRs, it flagged me for using auto function-calling mode where the rule expected required — but I'd moved the authoring agent off required a couple weeks ago and never updated the doc. The first bug it caught was me. The reviewer-build ended up being a good excuse to check in on which of my own rules were still current. I'm still shipping the reviewer, but I'll probably keep treating "do we have a reviewer rule for this?" as a checkpoint whenever design decisions evolve.
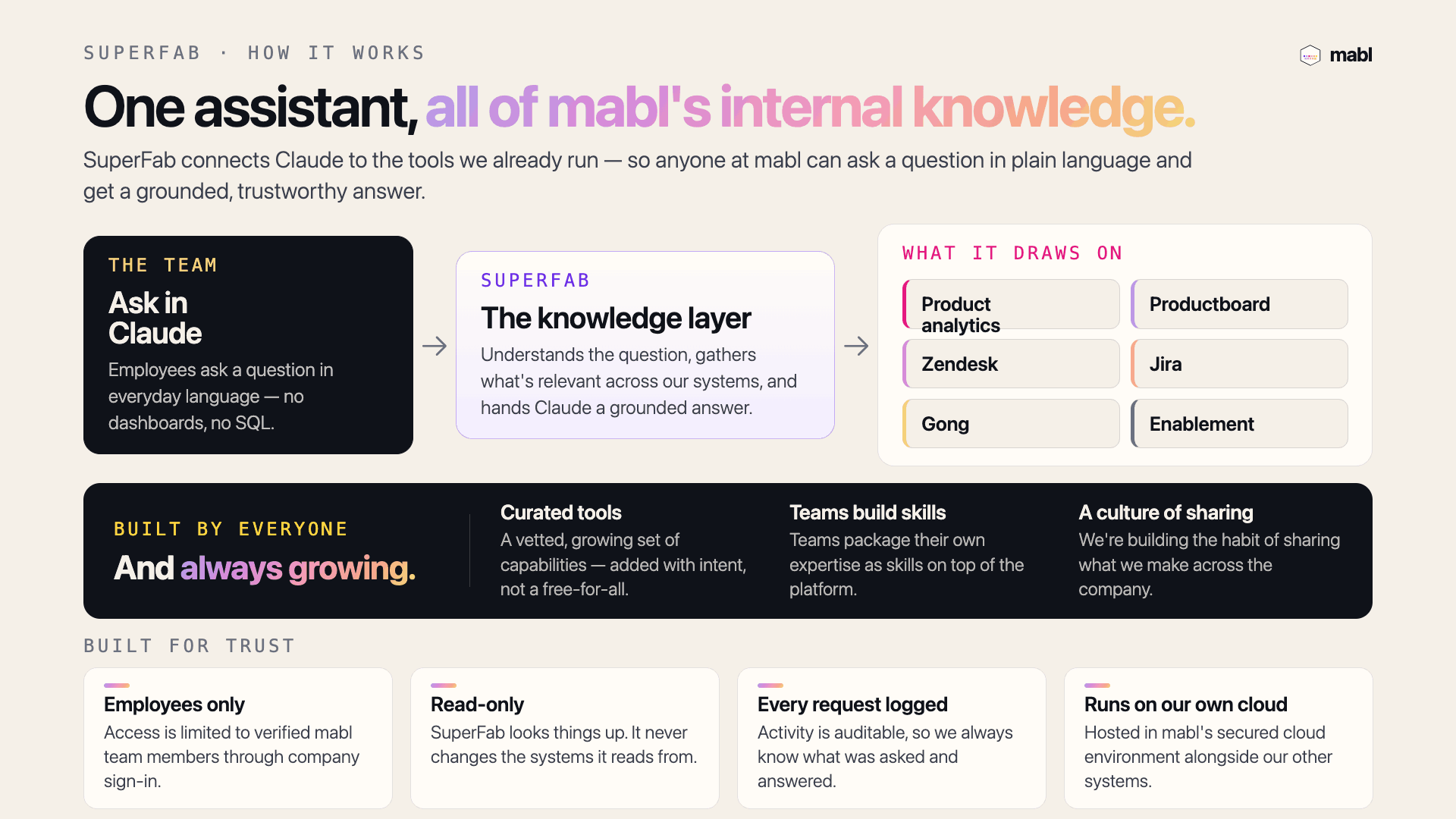
Last week we launched SuperFab, the agentic operating system for how we run mabl. The idea is simple: one assistant that connects Claude to the tools we already use, so anyone here can ask a question in plain language and get a grounded, trustworthy answer back. No dashboards, no SQL, no hunting through six systems.
We ran it as an internal hackathon, and people were contributing within hours. Folks in sales, marketing, customer success, product, and support were building and sharing their own skills on top of it, fast. They saw the thing work, recognized their own expertise was exactly what it was missing, and packaged it up so the rest of us could use it too.
Our next step is to look across everything people built and figure out how the foundation needs to change to support it: more secure, more flexible, easier to extend. The skills are running ahead of the platform right now, and that's what I'm focused on next.
I had a handful of PRs open at the same time last week, and the bottleneck wasn't the code — it was me remembering what each session was doing by the time I came back to it. You can't keep a chat window open for every PR. So I wrote a small skill: save dumps the current session to a file keyed by a pull request, and load brings it back when I return to that PR. If one piece of work spans three repos, it's stored once and I can reload it by any of the three PR numbers. When every PR in a memory gets merged, it quietly deletes itself in the background — I'm not going to garbage-collect my own notes. The whole store is local and gitignored, because this is my mess to keep, not the team's.
I plan a change with the agent, it opens a PR, and then I do what everyone does: go to GitHub to actually read the diff. GitHub is still the best place to read code. The problem is the round trip. I'd leave a comment there, switch back to the terminal, and then… what? Tell the agent to go read my comment on line 40? Paste it back myself? That's not reviewing, that's being a courier for my own feedback.
So I started using Hunk (not Hulk — Hunk: https://github.com/modem-dev/hunk). It opens a diff viewer that the agent and I are both looking at. I leave inline comments and the agent reads them right where I left them. No copy-paste, no relaying through chat.
The part I didn't expect: if a Hunk session is open, mauro-reviewer drops its review notes straight into it instead of the chat. So now I don't have to leave the diff to talk to the agent about the diff.
I've been in a lot of discussions lately about independent testing agents, why you'd want one separate from your coding agent, and what makes it different. It isn't really about the model. Part of why coding agents feel so autonomous is that the verification problem was mostly solved for them. They inherit compilers, linters, test runners, CI, source control. Structured feedback that tells them, precisely, whether they're right or wrong. The model is impressive, but it's standing on decades of verification infrastructure it never had to build.
An independent testing agent inherits almost none of that. What it acts on isn't source code, it's a running app: non-deterministic, stateful, changing under it, and nothing volunteers whether it succeeded. There's also a reason you want it independent. A coding agent checking its own work is grading its own homework. You want a separate agent whose only job is deciding whether the product behaves. So its harness has to be built from scratch, and I've been working out what's actually in it.
Start with acting. A testing agent has to do what a user does. It clicks through a web app, taps through a mobile app, calls an API, so the harness has to give it real hands on the product across every surface customers use. But that part is getting commoditized. Any capable model can drive a UI or hit an endpoint now. Executing a test isn't the hard problem anymore.
The hard problem is verification. How does the agent know a login actually worked, a checkout actually completed, a page rendered the way it should? Generating the action is easy-ish; deciding whether the result was right is the whole job. Without a verification layer you haven't built an autonomous tester. You've built an autonomous clicker.
Verification starts with observing, deeply, the way a user would and a tester would. The agent needs screenshots, DOM state, network activity, logs, traces, the runtime behavior. But collecting evidence isn't enough. The harness has to compare what it saw against what was expected and decide whether the behavior was correct, and that judgment is the hard, valuable part.
It also has to do that efficiently. Easy to wave away until you run it at scale. The naive version, where you hand the whole DOM, every screenshot, and all the network traffic to the model on every step and ask "did that look right?", costs enormous tokens and time for one verdict. A good harness runs the cheap deterministic checks deterministically, saves the model for the judgments that need it, and uses what it already knows about the app so it isn't reasoning from raw pixels each run. At the scale a real suite runs, that's the difference between viable and not.
And verification compounds. Every run produces knowledge: which selectors are stable, which flows matter, which failures are expected, which recoveries work. A real harness keeps that and hands it to the next run. Without it, the agent shows up as a brand-new tester every time it opens the browser. It's most of why pointing a general-purpose agent at a browser only gets you so far.
And none of it matters unless people trust the verdict. The agent touches credentials, environments, and real data, so it has to run inside the same controls a person would, and explain itself: what it did, why it decided what it decided, what it saw and concluded. The harness isn't only constraining the agent; it's making its work auditable.
So here's where I've landed. Coding agents got a head start because software already had a verification harness. Compilers, tests, CI, and version control all tell an agent when it's right and wrong. Testing doesn't come with one, so it has to be built. And the hard part was never getting the agent to act. It's getting it to know what happened, judge whether it was right without spending a fortune to do it, and leave behind evidence the rest of us can trust.
I've been thinking about how LLM coding costs scale across the life of a project, and I'm not sure the way we usually frame it holds up. Greenfield is where the velocity multiplier looks the best — small context, clean abstractions, low blast radius — and that's also where the per-change token cost is lowest. Both of those move in the wrong direction as the codebase gets bigger and harder to reason about. Each change pulls in more files, more constraints, and more historical decisions the model has to re-discover. The bill goes up while the speedup goes down. I'm guessing this gets worse on projects built primarily by LLMs, because the patterns the model laid down in the easy phase don't always hold up under the weight of real product complexity, and the inefficiencies are harder to spot when nobody hand-wrote them. That's a hunch, not a finding — I'd want to see real cost-per-feature curves on a few projects of comparable scope before I'd commit to it. But it's the question I keep coming back to when people quote a velocity multiplier without saying what month they measured it in.