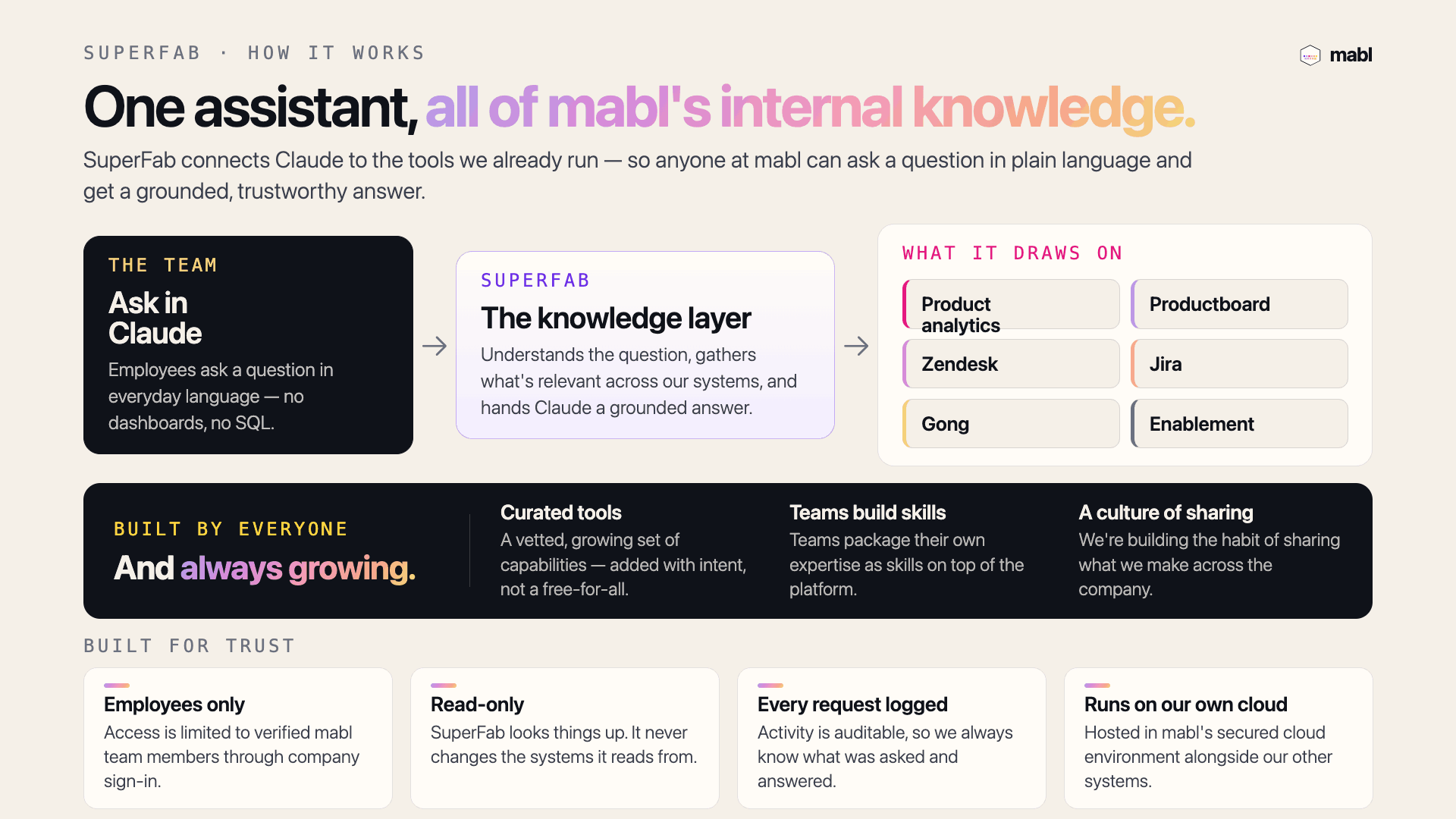
What makes a testing agent different from a coding agent?
I've been in a lot of discussions lately about independent testing agents, why you'd want one separate from your coding agent, and what makes it different. It isn't really about the model. Part of why coding agents feel so autonomous is that the verification problem was mostly solved for them. They inherit compilers, linters, test runners, CI, source control. Structured feedback that tells them, precisely, whether they're right or wrong. The model is impressive, but it's standing on decades of verification infrastructure it never had to build.
An independent testing agent inherits almost none of that. What it acts on isn't source code, it's a running app: non-deterministic, stateful, changing under it, and nothing volunteers whether it succeeded. There's also a reason you want it independent. A coding agent checking its own work is grading its own homework. You want a separate agent whose only job is deciding whether the product behaves. So its harness has to be built from scratch, and I've been working out what's actually in it.
Start with acting. A testing agent has to do what a user does. It clicks through a web app, taps through a mobile app, calls an API, so the harness has to give it real hands on the product across every surface customers use. But that part is getting commoditized. Any capable model can drive a UI or hit an endpoint now. Executing a test isn't the hard problem anymore.
The hard problem is verification. How does the agent know a login actually worked, a checkout actually completed, a page rendered the way it should? Generating the action is easy-ish; deciding whether the result was right is the whole job. Without a verification layer you haven't built an autonomous tester. You've built an autonomous clicker.
Verification starts with observing, deeply, the way a user would and a tester would. The agent needs screenshots, DOM state, network activity, logs, traces, the runtime behavior. But collecting evidence isn't enough. The harness has to compare what it saw against what was expected and decide whether the behavior was correct, and that judgment is the hard, valuable part.
It also has to do that efficiently. Easy to wave away until you run it at scale. The naive version, where you hand the whole DOM, every screenshot, and all the network traffic to the model on every step and ask "did that look right?", costs enormous tokens and time for one verdict. A good harness runs the cheap deterministic checks deterministically, saves the model for the judgments that need it, and uses what it already knows about the app so it isn't reasoning from raw pixels each run. At the scale a real suite runs, that's the difference between viable and not.
And verification compounds. Every run produces knowledge: which selectors are stable, which flows matter, which failures are expected, which recoveries work. A real harness keeps that and hands it to the next run. Without it, the agent shows up as a brand-new tester every time it opens the browser. It's most of why pointing a general-purpose agent at a browser only gets you so far.
And none of it matters unless people trust the verdict. The agent touches credentials, environments, and real data, so it has to run inside the same controls a person would, and explain itself: what it did, why it decided what it decided, what it saw and concluded. The harness isn't only constraining the agent; it's making its work auditable.
So here's where I've landed. Coding agents got a head start because software already had a verification harness. Compilers, tests, CI, and version control all tell an agent when it's right and wrong. Testing doesn't come with one, so it has to be built. And the hard part was never getting the agent to act. It's getting it to know what happened, judge whether it was right without spending a fortune to do it, and leave behind evidence the rest of us can trust.
An independent testing agent inherits almost none of that. What it acts on isn't source code, it's a running app: non-deterministic, stateful, changing under it, and nothing volunteers whether it succeeded. There's also a reason you want it independent. A coding agent checking its own work is grading its own homework. You want a separate agent whose only job is deciding whether the product behaves. So its harness has to be built from scratch, and I've been working out what's actually in it.
Start with acting. A testing agent has to do what a user does. It clicks through a web app, taps through a mobile app, calls an API, so the harness has to give it real hands on the product across every surface customers use. But that part is getting commoditized. Any capable model can drive a UI or hit an endpoint now. Executing a test isn't the hard problem anymore.
The hard problem is verification. How does the agent know a login actually worked, a checkout actually completed, a page rendered the way it should? Generating the action is easy-ish; deciding whether the result was right is the whole job. Without a verification layer you haven't built an autonomous tester. You've built an autonomous clicker.
Verification starts with observing, deeply, the way a user would and a tester would. The agent needs screenshots, DOM state, network activity, logs, traces, the runtime behavior. But collecting evidence isn't enough. The harness has to compare what it saw against what was expected and decide whether the behavior was correct, and that judgment is the hard, valuable part.
It also has to do that efficiently. Easy to wave away until you run it at scale. The naive version, where you hand the whole DOM, every screenshot, and all the network traffic to the model on every step and ask "did that look right?", costs enormous tokens and time for one verdict. A good harness runs the cheap deterministic checks deterministically, saves the model for the judgments that need it, and uses what it already knows about the app so it isn't reasoning from raw pixels each run. At the scale a real suite runs, that's the difference between viable and not.
And verification compounds. Every run produces knowledge: which selectors are stable, which flows matter, which failures are expected, which recoveries work. A real harness keeps that and hands it to the next run. Without it, the agent shows up as a brand-new tester every time it opens the browser. It's most of why pointing a general-purpose agent at a browser only gets you so far.
And none of it matters unless people trust the verdict. The agent touches credentials, environments, and real data, so it has to run inside the same controls a person would, and explain itself: what it did, why it decided what it decided, what it saw and concluded. The harness isn't only constraining the agent; it's making its work auditable.
So here's where I've landed. Coding agents got a head start because software already had a verification harness. Compilers, tests, CI, and version control all tell an agent when it's right and wrong. Testing doesn't come with one, so it has to be built. And the hard part was never getting the agent to act. It's getting it to know what happened, judge whether it was right without spending a fortune to do it, and leave behind evidence the rest of us can trust.