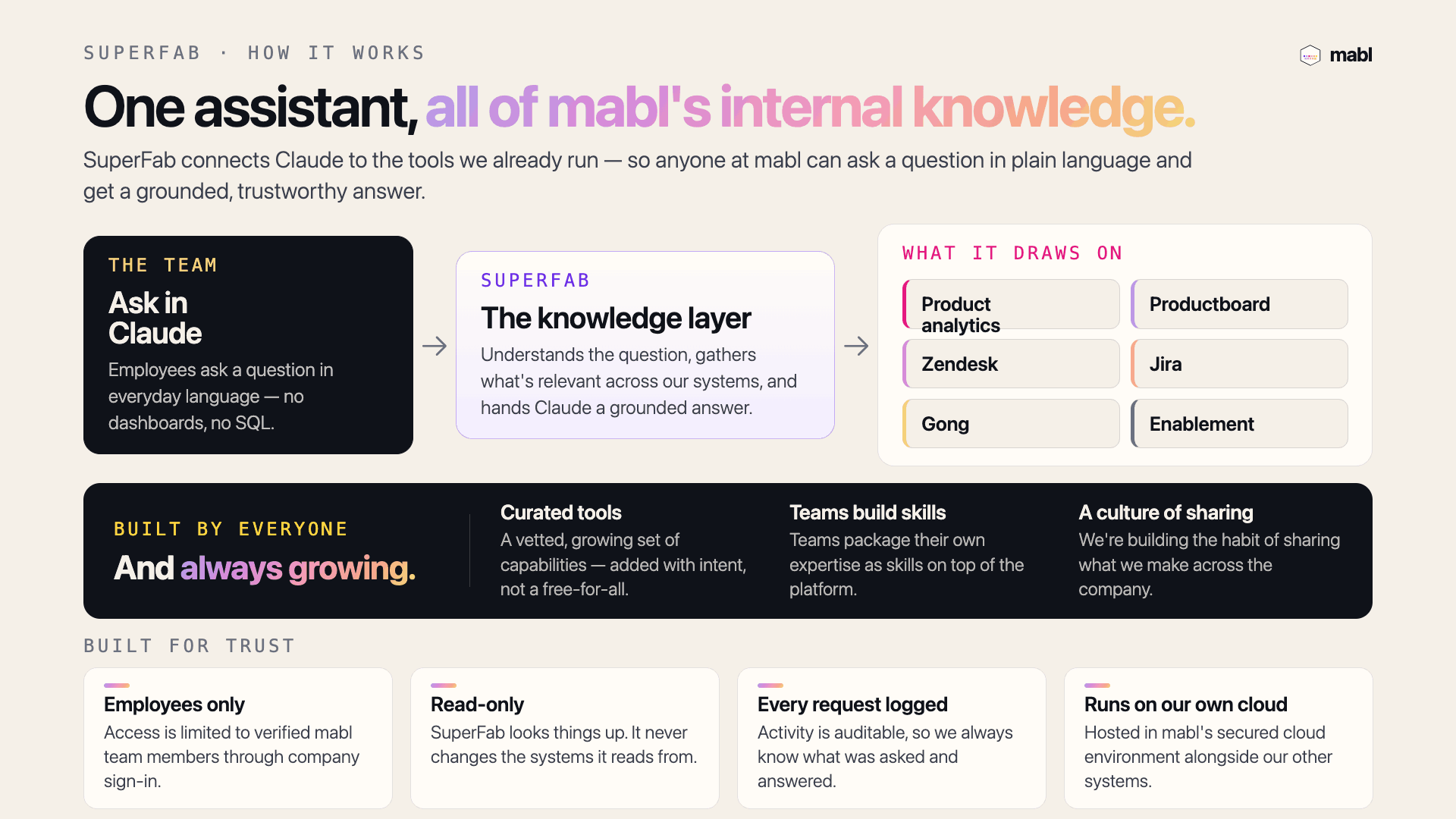
Last week we launched SuperFab, the agentic operating system for how we run mabl. The idea is simple: one assistant that connects Claude to the tools we already use, so anyone here can ask a question in plain language and get a grounded, trustworthy answer back. No dashboards, no SQL, no hunting through six systems.
We ran it as an internal hackathon, and people were contributing within hours. Folks in sales, marketing, customer success, product, and support were building and sharing their own skills on top of it, fast. They saw the thing work, recognized their own expertise was exactly what it was missing, and packaged it up so the rest of us could use it too.
Our next step is to look across everything people built and figure out how the foundation needs to change to support it: more secure, more flexible, easier to extend. The skills are running ahead of the platform right now, and that's what I'm focused on next.
We wanted to know how mabl engineers actually track a PR through CI now, so we polled the team: do you watch the GitHub Actions UI, or just ask Claude in the terminal where you made the change? It came back almost exactly 50/50.
Half the team still opens the dashboard, watches the checks spin, clicks into a red job, scrolls the log. The other half doesn't open the browser at all: they ask "where's my PR, is it green, what failed," and let the agent watch the run and report back the line that matters. Same task, two completely different interfaces, split right down the middle.
So which way does that split move? Is there a lasting place for a dashboard in the dev workflow, something you look at? Or does the whole thing get orchestrated through the chat interface, where you ask instead of watch? I genuinely don't know yet, and I want to see how it evolves over the next few months.
It's not an idle question for us. The answer shapes our own product integration priorities, how much we invest in things you watch versus things you talk to. We'll watch closely in the coming weeks to see how the split shifts internally and across our customer base.
I've been in a lot of discussions lately about independent testing agents, why you'd want one separate from your coding agent, and what makes it different. It isn't really about the model. Part of why coding agents feel so autonomous is that the verification problem was mostly solved for them. They inherit compilers, linters, test runners, CI, source control. Structured feedback that tells them, precisely, whether they're right or wrong. The model is impressive, but it's standing on decades of verification infrastructure it never had to build.
An independent testing agent inherits almost none of that. What it acts on isn't source code, it's a running app: non-deterministic, stateful, changing under it, and nothing volunteers whether it succeeded. There's also a reason you want it independent. A coding agent checking its own work is grading its own homework. You want a separate agent whose only job is deciding whether the product behaves. So its harness has to be built from scratch, and I've been working out what's actually in it.
Start with acting. A testing agent has to do what a user does. It clicks through a web app, taps through a mobile app, calls an API, so the harness has to give it real hands on the product across every surface customers use. But that part is getting commoditized. Any capable model can drive a UI or hit an endpoint now. Executing a test isn't the hard problem anymore.
The hard problem is verification. How does the agent know a login actually worked, a checkout actually completed, a page rendered the way it should? Generating the action is easy-ish; deciding whether the result was right is the whole job. Without a verification layer you haven't built an autonomous tester. You've built an autonomous clicker.
Verification starts with observing, deeply, the way a user would and a tester would. The agent needs screenshots, DOM state, network activity, logs, traces, the runtime behavior. But collecting evidence isn't enough. The harness has to compare what it saw against what was expected and decide whether the behavior was correct, and that judgment is the hard, valuable part.
It also has to do that efficiently. Easy to wave away until you run it at scale. The naive version, where you hand the whole DOM, every screenshot, and all the network traffic to the model on every step and ask "did that look right?", costs enormous tokens and time for one verdict. A good harness runs the cheap deterministic checks deterministically, saves the model for the judgments that need it, and uses what it already knows about the app so it isn't reasoning from raw pixels each run. At the scale a real suite runs, that's the difference between viable and not.
And verification compounds. Every run produces knowledge: which selectors are stable, which flows matter, which failures are expected, which recoveries work. A real harness keeps that and hands it to the next run. Without it, the agent shows up as a brand-new tester every time it opens the browser. It's most of why pointing a general-purpose agent at a browser only gets you so far.
And none of it matters unless people trust the verdict. The agent touches credentials, environments, and real data, so it has to run inside the same controls a person would, and explain itself: what it did, why it decided what it decided, what it saw and concluded. The harness isn't only constraining the agent; it's making its work auditable.
So here's where I've landed. Coding agents got a head start because software already had a verification harness. Compilers, tests, CI, and version control all tell an agent when it's right and wrong. Testing doesn't come with one, so it has to be built. And the hard part was never getting the agent to act. It's getting it to know what happened, judge whether it was right without spending a fortune to do it, and leave behind evidence the rest of us can trust.
I compared engineering output from the last 90 days against the 90 days before it. PRs went from 811 to 2,068 — two and a half times more. Lines of code shipped almost doubled. The number of active authors barely moved, from 31 to 35, so almost all of the lift is per-engineer throughput, not headcount. The other thing the data shows is that PR count grew faster than LOC, which means PRs are getting smaller on average — more, tighter changes instead of bigger ones. Reviews almost doubled too, which tracks. The thing I'm looking for now is the bottleneck. What's actually holding people back at this throughput — human review, testing, scoping, something else? That's where I want to spend the next month.
I've been watching what our two PR reviewers actually catch, and the pattern is uncomfortable. Our default review runs on Claude. Anyone can also kick off a Codex review on demand — and when they do, Codex regularly flags blocking issues the Claude pass walked right by. Not edge cases. Things that would have shipped.
The honest question: is Codex better at code review, or is the win mostly that it's a second perspective looking at the same diff? If we'd built it the other way around — Codex by default, Claude on demand — would we be writing this post about Claude?
I don't know yet, and I think that's the right place to sit for a minute before we draw the conclusion. What I do know is that on the changes that matter, two reviewers from two different shops are catching more than one of either, and that's a finding regardless of which is "better." We're going to keep both, and I'm going to start measuring which class of issue each one actually catches.
I rewrote the workspace menu on a branch this weekend, swapping a Bootstrap dropdown for a Material-UI button, and the mabl remote MCP told me — in the PR, before I'd merged anything — that I'd just broken every mabl-on-mabl test that goes through login. The agent walked the chain: get_mabl_deployment surfaced the failing deploy preview runs, analyze_failure produced the root-cause synopsis, and get_mabl_test_details located the offending step. Our "App - Login" reusable flow asserts on a specific selector to confirm the workspace dropdown is present. My rewrite replaced that control with one mabl's intelligent find recognizes natively — so the right fix is to delete the brittle assertion and let intelligent find do its job. The agent proposed both: a one-line backwards-compat id to unblock the PR today, and a follow-up to clean up the e2e flow at leisure. Ten seconds in context. I'd have caught this at deploy time without the MCP; I caught it while I was still in the diff.
I tried to make /fab-note auto-publish posts the moment a draft is confirmed. Two paths to do that, and both required carving an exception out of our org's branch protection — either a bot identity in the bypass list or a PAT scoped to repository admin. Neither is wrong, but each is a small concession against the policy that says "every change to main gets reviewed." So I stopped pushing on auto-merge and made the workflow assign the PR to me instead. Total clock time from "ship it" to live: about two minutes — most of it CI checking. The clicks in between (one approval, one merge) take three seconds and they preserve the property that a human approved the change. I was solving for the wrong thing. The friction of "wait for CI, click approve, click merge" is invisible to the author because they've moved on to the next thing by the time it's their turn. The friction of "build a policy exception around a fast publish path" is permanent and visible to anyone who later asks why this repo bypasses the rules. The cheapest version of automation is the one that lets the existing policy do its job.
I wanted to stand up an engineering log at fab.mabl.com — short posts from people on the delivery pipeline, public, in our voice. The first instinct was the obvious one: a CMS, or markdown files in a repo with a PR per post. Both are wrong for us. A CMS adds a vendor for ten posts a year. A PR per post means Joey doesn't write the post, because forking and branching to publish a paragraph isn't how anyone gets a paragraph out of their head. So we did the third thing: posts are markdown files in the repo, and the authoring interface is a Claude skill called /fab-note that drafts a post in the established voice, confirms it with the author, and commits the file directly to main. The author never sees a PR. Git history is preserved. The skill is the CMS. The point that surprised me writing this: the right interface for a publishing system isn't a form or a PR, it's the tool the authors are already inside. Our engineers spend their day in Claude Code. Meeting them there cost less than building anything else.