Sorry Claude, Gunna Need You to Come in on Saturday
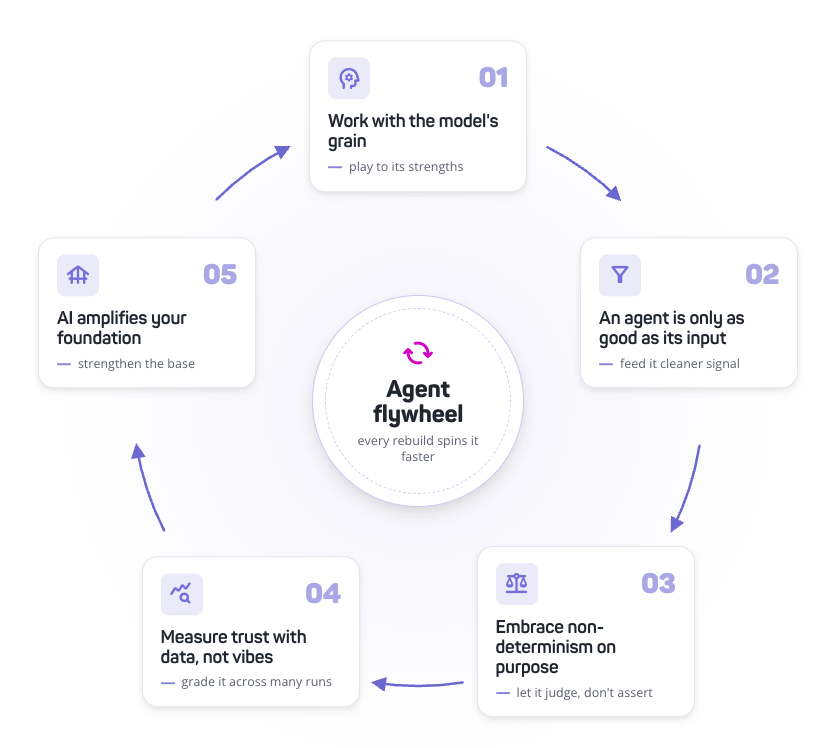
7 days in a week, 7 days in a token budget. Why is your agent at the beach on Saturday? Think of all the chunky tech debt projects nobody ever has time for. That's what agents are for.
I had an API with hundreds of endpoints, and I wanted to refactor every one of them to a more modern, robust, faster framework. Who has time to rotely refactor controllers and re-validate that _nothing_ broke? Claude does, with a
The whole thing is unlocked by tests we wrote years ago. Thousands of API-level validation tests and end-to-end suites for the web apps that consume the API — that's the feedback signal a
While you were at the beach worrying about how much sand your kids would track into the car, Claude burned down a major chunk of the tech debt backlog. LFG.
I had an API with hundreds of endpoints, and I wanted to refactor every one of them to a more modern, robust, faster framework. Who has time to rotely refactor controllers and re-validate that _nothing_ broke? Claude does, with a
/goal.The whole thing is unlocked by tests we wrote years ago. Thousands of API-level validation tests and end-to-end suites for the web apps that consume the API — that's the feedback signal a
/goal actually needs. "Get the suites green without changing the clients or the interfaces, only the server implementation." That's it. From there our CI does the rest: every PR spins up a deploy preview, fires the full cloud regression suite, and reports back. The agent runs permutations across branches in parallel and validates each one on its own.While you were at the beach worrying about how much sand your kids would track into the car, Claude burned down a major chunk of the tech debt backlog. LFG.