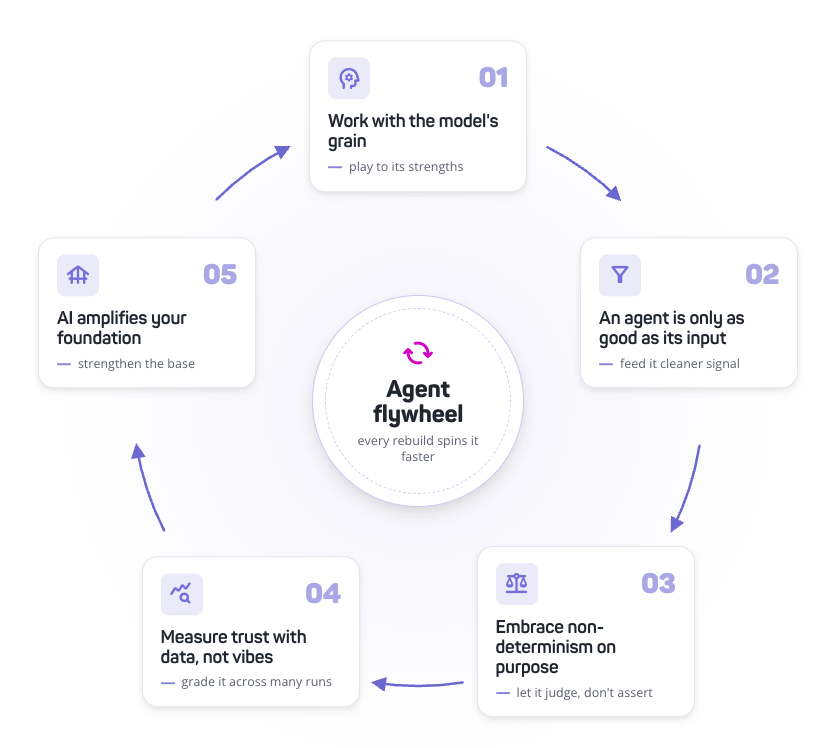
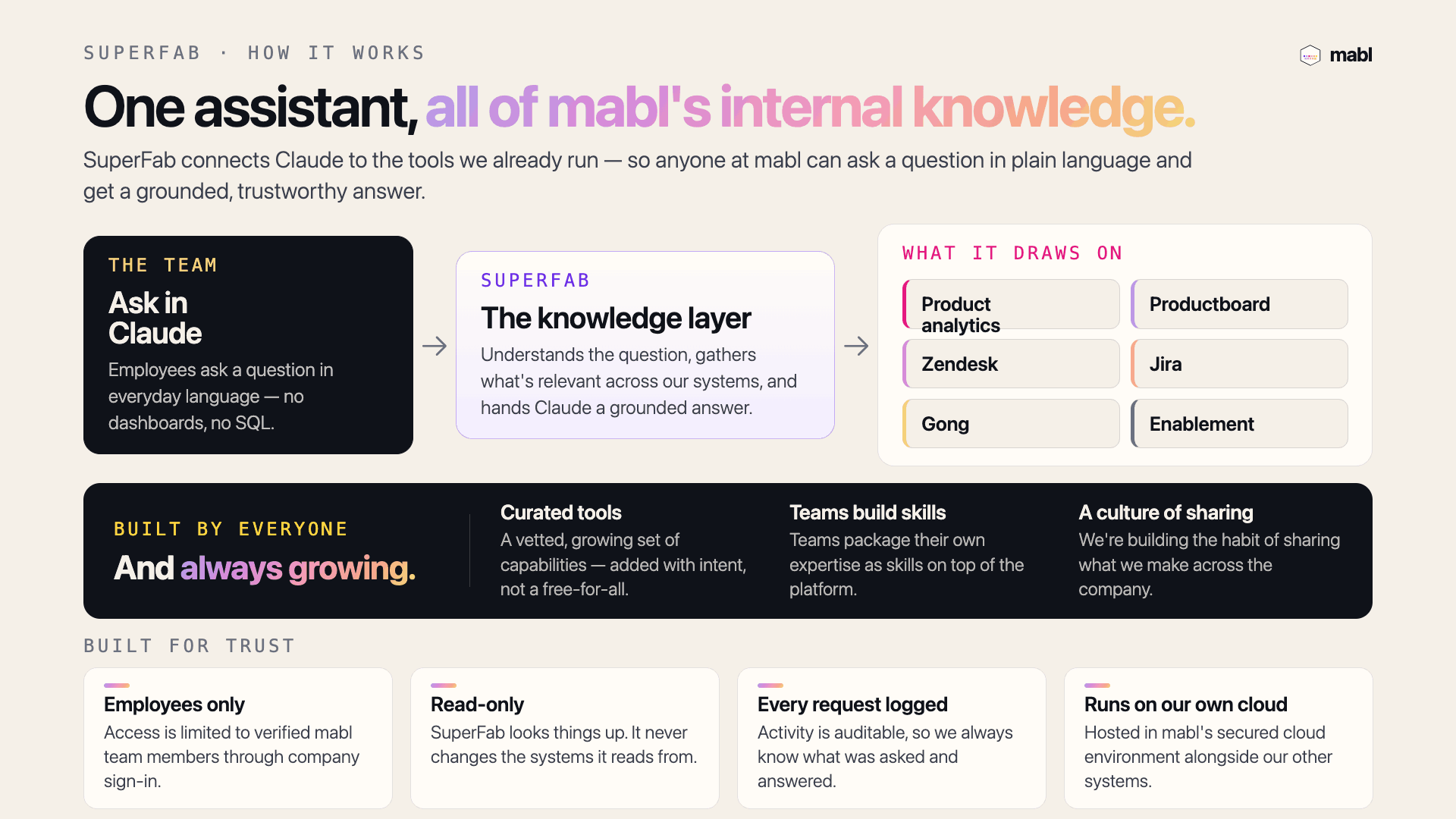
Eliminate the small stuff: automatic code styling FTW
Millions of PR comments a year get burned on style — tabs, spaces, imports, line breaks. That's a closed-form, solved problem. Why are you wasting your keystrokes and valuable context on style? We don't. No need to fill our CLAUDE.md files with 10 pages of format rules, no need for a new hire to spend a week learning our way to type. Don't fill your physical and virtual context windows with rules a CPU can apply.
So Spotless landed across our Java codebase this week, with a pre-commit hook and a CI check. I picked it specifically because it auto-fixes. Other tools will scold you about wildcard imports ("thou shalt not!"); Spotless will simply fix them, auto-magically. A tool that produces a report is the wrong pattern — at scale, we're shipping code, not reports. Calling "fix" is table stakes. The pre-commit hook means both human and agent operator styles are fixed before the PR opens. Neither has to grok the rules.
The goal isn't to sweat the small stuff. It's to eliminate it. I don't care how you use tabs or spaces. I care that your feature does what the customer needs. Leave the rest to the CPU. LFG.
So Spotless landed across our Java codebase this week, with a pre-commit hook and a CI check. I picked it specifically because it auto-fixes. Other tools will scold you about wildcard imports ("thou shalt not!"); Spotless will simply fix them, auto-magically. A tool that produces a report is the wrong pattern — at scale, we're shipping code, not reports. Calling "fix" is table stakes. The pre-commit hook means both human and agent operator styles are fixed before the PR opens. Neither has to grok the rules.
The goal isn't to sweat the small stuff. It's to eliminate it. I don't care how you use tabs or spaces. I care that your feature does what the customer needs. Leave the rest to the CPU. LFG.